P4 INT
带内网络遥测(In-band Network Telemetry,INT)是一种“让数据包自己把路上的事讲出来”的网络监控思路。
这份笔记是我在读 P4.org 的 INT 规范 时整理出来的。一开始只是零散翻译,后来发现直译下来的术语链很难让人理解“这到底在解决什么问题”,于是把整份内容重新梳理了一遍:先用生活化的例子建立直观,再一步步推进到报文格式与工程细节。
1 先回答一个问题:为什么要有 INT?
传统的网络监控基本只能拿到“设备自己愿意告诉你的东西”:
- SNMP / CLI 轮询:要主动去问交换机“你现在队列多长”,粒度是秒级甚至分钟级,微突发早就过去了。
- NetFlow / sFlow:看到的是采样后的聚合流统计,丢掉了单个包的行程信息。
- 控制平面汇报:控制器看到的永远是数据平面“过去某一时刻”的快照,和真实转发路径可能对不上。
这些方法有一个共同问题——监控动作和数据包本身是分离的。我们看到的指标是“设备说它大概是这样”,而不是“这一个包实际经历了什么”。
INT 换了一个角度:既然我想知道一个包走过了哪些设备、每一跳排队了多久,那就让包自己把这些信息带回来。每经过一个支持 INT 的节点,节点就把自己当时的状态(节点 ID、入/出端口、排队时延、队列深度……)按指令贴到包里;到达路径尽头时,接收端把这些信息抽出来送给监控系统。
换句话说:
INT 不是外部探针去问网络,而是把"探针"直接揉进了每一个数据包里。
这样拿到的是数据平面一手的、单包粒度的、带完整路径信息的状态,延迟低到可以用来做实时拥塞控制。
2 一个直观类比:盖章的包裹
把数据包想象成一个从 A 寄到 B 的包裹:
- 普通转发:中间每个快递点只看地址、换标签、继续发;到了 B 只知道包裹到了。
- SNMP 轮询:每隔几分钟给每个快递点打电话,问"你那边忙不忙",问到的永远是平均值。
- INT:包裹上多了一张指令卡:"请每个经手的快递点盖个章,写下时间、当前有多少件包裹在排队"。包裹到 B 时翻开章页,整条路径的情况一目了然。
这个类比对应到 INT 的三个角色:
- 寄件方 = INT Source:生成指令卡,决定要盖哪些字段。
- 中间快递点 = INT Transit:按指令盖章(插入元数据)或把信息直接快递回总部。
- 收件方 = INT Sink:撕掉指令卡,整理盖章记录,上报到"总部"(监控系统)。
后面所有术语,都可以先映射到这张图上,不容易被绕晕。
3 最小工作流:一个包从头走到尾
先不看任何报文格式,只看行为。假设一个 INT 包从 S 发出,经过 T1、T2,到达 D:
S ──► T1 ──► T2 ──► D
│ │ │ │
Source Transit Transit Sink- S(Source):根据流监控表(Flow Watchlist)命中了这条流,向包里插入 INT 头部,头部里写明"我想采集哪些字段"(Instruction Bitmap),比如节点 ID + 出端口 + 跳时延。
- T1、T2(Transit):看到 INT 头部,按指令把自己这一跳的元数据压栈进去。栈里越往后,是越靠近 D 的节点。
- D(Sink):把整个 INT 头部和元数据栈从包里剥掉,交给监控系统,业务包恢复成普通样子继续往上送。
这就是所谓的 INT-MD 模式——指令和数据都嵌在包里。后面会看到,INT 还有只嵌指令不嵌数据(MX)、甚至指令都不嵌(XD)的变体。
一个容易被忽略的点
同一个物理设备可以同时扮演多个角色。比如 Source 节点自己也会写一份元数据进去,它在逻辑上同时是 Source 和 Transit。
4 架构与术语
有了上面直觉,正式术语就顺了。这些概念会在后文反复出现,先在这里集中梳理:
| 术语 | 一句话理解 |
|---|---|
| INT 头部 | 包里用来承载 INT 信息的新字段,分 MD / MX / Destination 三类 |
| INT 包 | 身上带着 INT 头部的数据包 |
| INT 节点 | 能看懂并处理 INT 头部的交换机/路由器/网卡 |
| INT 指令 | 告诉节点"要采集哪些元数据"的位图,可以写在包头里,也可以配在流表里 |
| 流监控表 (Flow Watchlist) | 数据平面的一张匹配表:命中的流要做 INT |
| INT Source / Transit / Sink | 三个角色:插入头部 / 沿路盖章 / 剥掉头部并上报 |
| INT 元数据 | 每跳采集的那一块信息(节点 ID、时延、队列深度等) |
| INT 域 (Domain) | 一组同一管理下的 INT 节点;建议在域边界部署 Sink,避免信息泄露出域 |
| 监控系统 | 最终收遥测数据的地方,物理上可分布、逻辑上视为集中 |
有了这张表,再读规范原文就不会卡在"Transit Hop 到底是谁"这种问题上。
5 三种运行模式:嵌多少、嵌什么
INT 最早只有"指令和数据都塞进包里"的经典玩法,但它很快被各种变体扩展。规范按照包被改动了多少把 INT 分成三种模式,一张图对照着看就清楚了:
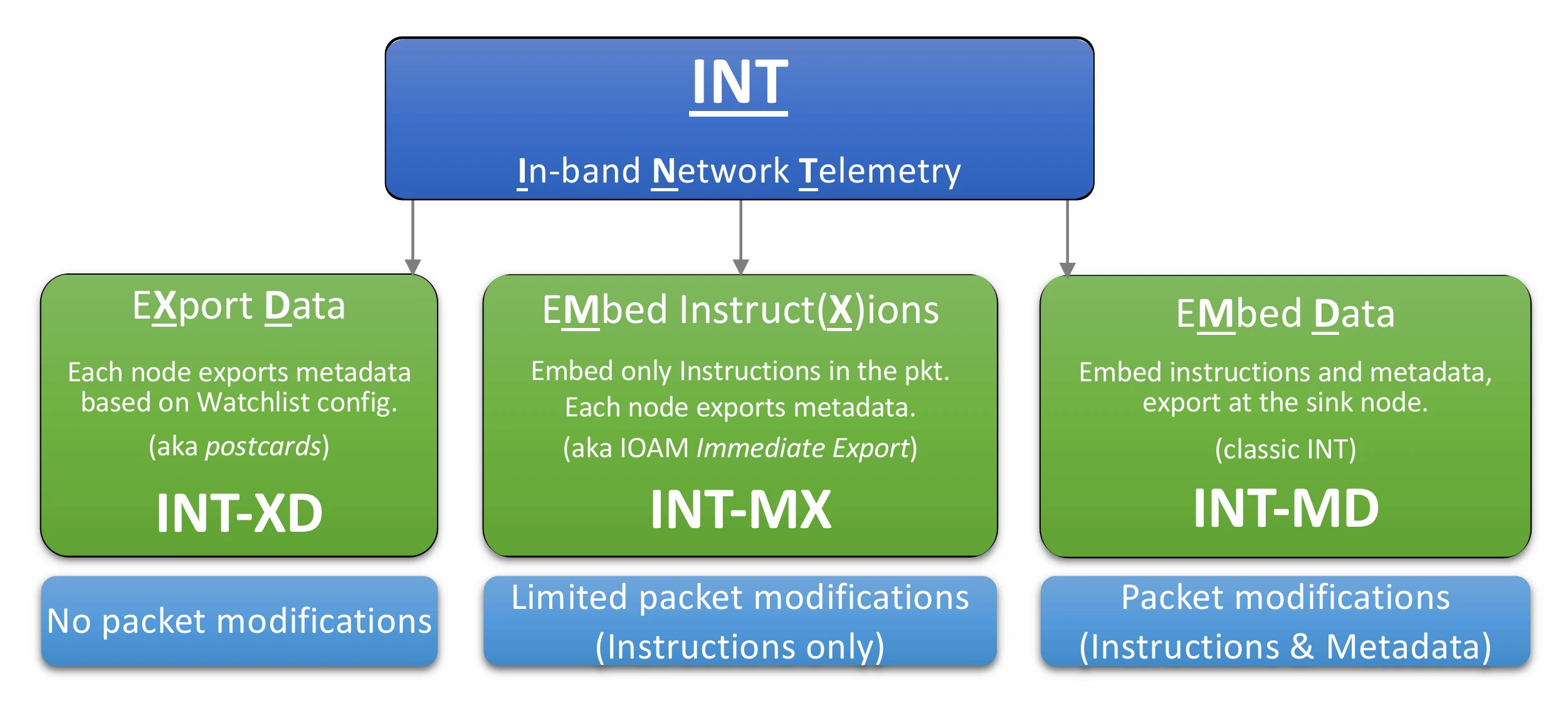 图 1. INT 的三种运行模式
图 1. INT 的三种运行模式
| 模式 | 包里嵌什么 | 谁来写入 | 谁来上报 |
|---|---|---|---|
| INT-XD | 什么都不嵌 | 无 | 每个节点直接把元数据导给监控系统 |
| INT-MX | 只嵌指令 | Source 写指令 | 各节点按指令各自上报 |
| INT-MD | 嵌指令 + 数据栈 | Source 写指令,Transit 逐跳压栈 | Sink 一次性剥出后上报 |
5.1 INT-XD:包不动,节点各自汇报
eXport Data,也叫"明信片(Postcard)"模式。节点根据本地流监控表里配的指令,直接把元数据导给监控系统,包本身一个字节都不改。
- 优点:对数据平面零侵入,原包不需要扩容、不碰 MTU。
- 代价:监控系统要负责把不同节点的上报,按 5 元组 + 时间戳重新拼回一条路径——聚合开销全压给后端。
这个思路最早来自 Handigol 等人的论文。
Postcard 机制出处
Handigol, Nikhil, Brandon Heller, Vimalkumar Jeyakumar, David Mazières, and Nick McKeown. "I know what your packet did last hop: Using packet histories to troubleshoot networks." In 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), pp. 71-85. 2014.5.2 INT-MX:只嵌指令,元数据各自寄回
eMbed instructions。Source 在包里写一段 INT-MX 头部,里面装的是指令位图。沿路每个节点看到指令后,自己决定要采哪些字段,然后直接把采到的数据走遥测报告发回监控系统,而不是塞回包里。Sink 在转发之前把指令头剥掉。
- 相对 XD 的好处:采集什么由 Source 统一决定,全路径口径一致;不像 XD 每个节点都要靠本地配置。
- 相对 MD 的好处:包的长度只增加一个固定大小的指令头,不会随跳数膨胀。
- 这个思路借鉴自 IETF 的 IOAM 直接导出模式。
IOAM
- F. Brockners, S. Bhandari, and T. Mizrahi. 2022. RFC 9197: Data Fields for In Situ Operations, Administration, and Maintenance (IOAM). RFC Editor, USA.
- H. Song, B. Gafni, F. Brockners, S. Bhandari, and T. Mizrahi. 2022. RFC 9326: In Situ Operations, Administration, and Maintenance (IOAM) Direct Exporting. RFC Editor, USA.
5.3 INT-MD:经典玩法,指令和数据都塞在包里
eMbed Data,也就是 §3 最小工作流里描述的那种:
- Source 写入 INT-MD 头部(含指令);
- Source + 每个 Transit 按指令把自己的元数据压栈进包里;
- Sink 把头部和整个元数据栈一并剥出,再视需要上报。
- 优点:所有跳的信息在一个包里天然按路径顺序聚好,监控系统几乎不需要再做聚合。
- 代价:每跳都增加包长,会直接撞到 MTU 限制(§9.1 会专门讨论);跳多时栈也会变大。
自 INT 规范 2.0 起,MD 模式也支持"仅源端插入"的元数据,作为域专用指令的一部分,让 Source 可以附带一些路径无关的上下文。
默认模式
后文讨论报文格式时,如果不特别说明,默认都是 INT-MD 模式——它是 INT 最具代表性、也最复杂的形态。搞懂了 MD,MX 基本是它的"砍掉数据栈"版本。
5.4 附加玩法:探测包和克隆包
前面讲的都是"在真实业务流量上加遥测"。但 INT Source 也可以自己造包专门用来探路——克隆一份原始包,或直接构造一个探测包(probe packet)。对中间节点来说,这类合成流量和普通 INT 包没有任何区别,照常处理。
区别只在终点:Sink 收到后通常要把合成包丢掉,而不是继续往上转。INT 头部里的 D 位(Discard Bit) 就是干这个用的——Source 把 D 位置 1,Sink 看到就知道"提完数据就地销毁"。
把 INT-MD 模式用在探测包上,效果基本等同于 IETF 的 IFA。
IFA
@techreport{kumar-ippm-ifa-08,
number = {draft-kumar-ippm-ifa-08},
type = {Internet-Draft},
institution = {Internet Engineering Task Force},
title = {{Inband Flow Analyzer}},
year = 2024, month = apr, day = 26,
url = {https://datatracker.ietf.org/doc/draft-kumar-ippm-ifa/08/},
}6 数据到了监控系统,能拿它做什么?
把视角拉回应用层。遥测数据收上来以后,Sink(或监控系统)根据场景可以走三条典型路线:
- 运维监控(OAM):把采到的原始或经加工(压缩、去重、截断)的数据平面状态上传控制器,供事后分析。
- 实时控制反馈:根据遥测结果立刻给流量源反信号——例如告诉发送端换路径、降速率。ECN 就是一种最朴素的反馈控制。
- 网络事件检测:识别拥塞热点或数据平面不变量被打破的情况,立即触发响应。这种响应可以集中式(由控制器下发),也可以像 TCP 那样完全分布式。
Transit 也可以发起
虽然上面三种行为通常由 Sink 做,但如果 Transit 节点自己观察到本地的异常(比如队列爆了),它也可以直接发 OAM 事件,不必等到 Sink。
基于这三类行为,INT 支撑了一批非常实用的上层场景:
- 排障与性能监测:路径追踪(Traceroute)、微突发检测、数据包历史记录(即前面提到的"明信片"机制)。
- 高级拥塞控制:利用实时遥测比 ECN 更灵敏地调节发送速率。
- 智能路由:基于链路利用率做负载均衡,代表方案如 HULA 和 CLOVE。
- 数据平面验证:用 INT 轨迹来核对网络实际行为和预期是否一致。
具体用例和评估可以看 Millions of Little Minions。
HULA
Naga Katta, Mukesh Hira, Changhoon Kim, Anirudh Sivaraman, and Jennifer Rexford. 2016. HULA: Scalable Load Balancing Using Programmable Data Planes. In Proceedings of the Symposium on SDN Research (SOSR '16). ACM, Article 10, 1–12. https://doi.org/10.1145/2890955.2890968
CLOVE
Naga Katta, Aditi Ghag, Mukesh Hira, Isaac Keslassy, Aran Bergman, Changhoon Kim, and Jennifer Rexford. 2017. Clove: Congestion-Aware Load Balancing at the Virtual Edge. In Proceedings of CoNEXT '17. ACM, 323–335. https://doi.org/10.1145/3143361.3143401
Millions of Little Minions
Vimalkumar Jeyakumar, Mohammad Alizadeh, Yilong Geng, Changhoon Kim, and David Mazières. 2014. Millions of little minions: using packets for low latency network programming and visibility. In Proceedings of SIGCOMM '14. ACM, 3–14. https://doi.org/10.1145/2619239.2626292
7 能采集哪些元数据?
理论上 INT 什么设备内部状态都能采,但规范优先定义了一组在多种硬件上都能落地的基础集合。
各项元数据的精确语义(时间戳单位、跳时延的计算方式、队列深度是字节还是包数……)不同厂商实现未必一致。规范的态度是:让实现自由,但要把语义通过带外模型共享出去——IETF 为此在做一份基于 YANG 的元数据语义模型,让收数据的一端能准确解读。
YANG model
p4-dtel-metadata-semantics, https://github.com/p4lang/p4-applications/blob/master/telemetry/code/models/p4-dtel-metadata-semantics.yang
按采集位置,基础元数据分成三类:
7.1 设备级
- Node ID:INT 节点在域内的唯一编号,由管理员配置,用于标识数据来源。
7.2 入方向
- Ingress Interface ID:包进来时用的接口。物理接口可能嵌在 LAG → SVI → Tunnel 这样的多层堆栈里,规范建议最多报两层——物理端口(16 位)和逻辑接口(32 位)。具体报哪一层由节点自己决定。
- Ingress Timestamp:包进入入接口时的本地时间。
7.3 出方向
出方向元数据是排障和拥塞控制真正关心的重点:
- Egress Interface ID:和入接口同样的两层模型。
- Egress Timestamp:包离开出接口时的本地时间。
- Hop Latency:包在本设备内被处理的时延(收到 → 发出)。
- Egress TX Link Utilization:出接口的实时带宽占用率。具体算法(桶计数 / 滑动平均 / ……)由实现决定,滑动平均效果通常更好。
- Queue Occupancy:当前出队列积压量。4 字节字段,单位是字节 / 包 / 单元由实现决定,语义由 YANG 模型描述。
- Buffer Occupancy:多队列共享缓冲时,整个 Buffer 的积压量,字段和语义约定同上。
经验
排障时最常用的四样是 Node ID、Hop Latency、Queue Occupancy 和 Egress Timestamp——几乎能回答"这个包在哪一跳慢下来的、慢了多少、因为谁在排队"这三个核心问题。
8 INT 头部格式
从这里开始进入"数据平面里真正发生的事"。这一节讲的内容只适用于需要在包里放点东西的 INT-MX 和 INT-MD 模式(INT-XD 完全不碰包,用不上这一节)。
8.1 先整体上认识三种头部
规范一共定义了三种 INT 头部类型,关系如下:
| 类型 | 谁处理 | 作用 |
|---|---|---|
| MD(Type 1) | Source / Transit / Sink 都处理 | 承载指令 + 逐跳元数据栈(详见 §8.6) |
| MX(Type 3) | Source / Transit / Sink 都处理 | 只承载指令,元数据直接上报(详见 §8.7) |
| Destination(Type 2) | 仅 Sink 处理,Transit 必须忽略 | 做"端到端"用途,比如塞序列号检测丢包、用 IP TTL + 剩余跳数对比推断路径上有没有不支持 INT 的设备 |
一个 INT 包里可以带 MD 或 MX 之一,以及(可选的)一个 Destination 头部。如果两个都带,MD/MX 必须在 Destination 前面。Destination 头部的具体格式留待后续版本定义。
8.2 每一跳要做什么
按角色拆开看:
Source 节点:在路径起点,负责构造 INT-MD / INT-MX 头部。MD 模式下还要附上自己的那份元数据;同时强烈建议设好 Remaining Hop Count,给后续 Transit 能写的条数上一个上限,防止环路把栈写爆。
Transit 节点:
- MD 模式:按指令把自己这一跳的元数据压栈进 INT 头部,并递减 Remaining Hop Count。
- MX 模式:按指令采集本地元数据,通过遥测报告送回监控系统。
- 两种模式下,都可以改
DS Flags,但不允许改Hop ML、Instruction Bitmap、Domain Specific ID、DS Instruction——这些由 Source 定调,沿路不能篡改。
Sink 节点:
- MD 模式:剥掉 INT 头部和整个元数据栈,视需要上报。
- MX 模式:剥掉 INT-MX 头部,采集本地元数据,视需要上报。
8.3 MTU:INT 会不会把包撑爆?
MD 模式下,每加一跳就往包里塞一段元数据,包会越走越长,撞上出口链路 MTU 几乎是必然。规范给了几种应对:
方案 A(推荐):提前留出余量。Source 和 Sink 之间的链路 MTU 配得比服务器/虚机网卡的 MTU 多出一块:
MD 模式需要预留:
Hop ML × 4 × 最大 INT 跳数 + 固定 INT 头部长度 字节
MX 模式只需预留:
固定 INT 头部长度 字节固定 INT 头部长度 = 12 字节(INT 元数据头) + 4 字节(封装特定的 shim/选项头),共 16 字节(详见 §8.5)。
方案 B:参与 Path MTU Discovery。Source 或 Transit 可以按 IPv4(RFC 1191)/ IPv6(RFC 1981)的机制,向流量源发 ICMP 报告一个保守的 MTU 估算值——假设下游每一跳都会继续写满。这样源端能尽快收敛,代价是估得偏紧。更激进的做法是每一跳只报自己这段增量,估算更准但 ICMP 会更多。
真的写不下怎么办? 如果某 Transit 插入全部请求的元数据会让包超 MTU,它必须二选一:
- 啥也不插,但要在 INT 头部把 M 位置 1,标识"此跳 MTU 超限"。
- 先把栈里前几跳的元数据报告出去(如果是 Telemetry Report 2.0,同时置 Intermediate Report 位),然后把栈清空,再把本跳元数据填上,让后续跳继续用。
Source 自己也可能遇到 MTU 问题。如果连 12 字节的固定 INT 头都塞不下,这个包就不能启动 INT;如果头塞得下但自己的元数据塞不下,就正常启动 INT,但把 M 位置 1。
不要用 IP 分片绕开 MTU
理论上 Transit 可以用 IPv4 分片绕开出口 MTU,但:(1)分片对应用不友好;(2)IPv6 中间节点根本不允许分片;(3)带 INT 元数据的分片会让后端聚合逻辑变得非常复杂。规范建议 INT 节点不对数据包做分片。
8.4 拥塞与校验和:别把网络搞乱
拥塞。INT 封装本身不应加剧拥塞。TCP / SCTP / DCCP / QUIC 自带拥塞控制;UDP 没有,这就要求应用层自己限流。规范明确建议不要对已知没有拥塞控制的流量启用 INT(参见 RFC 8085 §3.1.11),并应提供基于 IP 协议号 / L4 端口的 ACL 过滤。运营者如果一定要开,必须自己评估影响,辅以容量规划、流量工程、速率限制。
校验和。INT 头部经常会承载在 TCP/UDP 或含 L4 的封装(如 VXLAN)里。只要 INT 节点改了 L4 有效载荷(插入或删除元数据),就必须更新 TCP/UDP 校验和。
几个例外:
- IPv4 上的 UDP 允许校验和为 0(RFC 768)——收到零校验和就别动它。
- IPv6 上的 UDP 有些场景也允许零校验和(RFC 6936)——同样别动。
更新校验和有两种做法:
- 直接改:重新算出正确的 L4 校验和写进去。
- Checksum Complement 中性更新:Source 在指令位里允许后,Source 或 Transit 插入一个补偿字段,让整个 L4 载荷的校验和"看起来像是没变",原 L4 校验和字段完全不动。Checksum Complement 必须是元数据栈里的最后一项。
Sink 不能用 Checksum Complement
Sink 会把 INT 字段全部剥掉,补偿字段也跟着没了,只能走"直接改校验和"这条路。
无论哪种方式,都建议使用增量校验和算法,并在重算前先验证一次已有的校验和——防止掩盖前一跳发生的损坏。
8.5 INT 头部放在哪里?
规范不限制 INT 头部的绝对位置,只要求:封装层留出足够空间、域内所有节点对位置达成一致。自 v2.0 起,规范推荐以下几种典型组合:
- INT over IPv4/GRE:插在 GRE 头与被封装的负载之间。
- INT over TCP/UDP:L4 头之后加 shim 层,再放 INT 头;或在原 L4 头前再加一层 UDP,然后放 INT 头。后者不需要任何隧道或虚拟化,原生和虚拟流量都能用。
- INT over VXLAN:借助 VXLAN 的 GPE 扩展,插在 VXLAN 头与负载之间。
- INT over Geneve:作为 Geneve 选项字段插入,这是 Geneve 最自然的用法。
- INT over NSH:作为 NSH 负载插入。
8.6 深入 INT-MD 头部
INT-MD 头固定 12 字节,后面跟一个可变长度的元数据栈:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Ver = 2|D|E|M| Reserved | Hop ML |RemainingHopCnt|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Instruction Bitmap | Domain Specific ID |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| DS Instruction | DS Flags |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| INT 元数据堆栈(每跳 Hop ML × 4 字节) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| ...... |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 最后一跳 INT 元数据 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+字段拆解
先看控制部分:
- Ver(4 位):版本号,当前固定为 2。
- D(1 位):Discard,置 1 时 Sink 在提完数据后直接丢包。
- E(1 位):Exceeded,当
RemainingHopCnt已经降到 0、当前节点又想写元数据时置 1。Source 初始化为 0。 - M(1 位):MTU Exceeded,当前节点写不下(§8.3)就置 1 并不插任何元数据。
- Reserved(12 位):Source 写 0,其他节点忽略。
- Hop ML(5 位):Hop Metadata Length,以 4 字节为单位,规定每个 Transit 要写多长的元数据(不含"源端专用"部分),由 Source 设定。
- RemainingHopCnt(8 位):剩余还能写几跳。每个实际写入的节点把它减一;为 0 时不得再写。
再看指令部分:
- Instruction Bitmap(32 位):标准元数据的位图,每个 bit 对应 §7 里的一个字段。
- Domain Specific ID / DS Instruction / DS Flags:成对工作。DSID = 0x0000 表示默认域,此时 DS Instruction 无效;否则用 0x0001–0xFFFF 由运营者自行分配。DS Instruction 里有些位可以被定义成"仅源端插入",只有 Source 写。
元数据栈:压栈顺序和对齐
栈里的内容由沿路节点按 Instruction Bitmap 和 DS Instruction 里置位的顺序写入。每跳往栈顶压(push),因此最先到达接收端视角的栈顶对应的是最后一跳。Checksum Complement 如果有,必须是栈中最后一项。
栈总长度必须是 Hop ML × 4 的整数倍(加上可选的源端专用元数据),可以用下式反推:
INT 元数据总长度 = (INT Shim Header 长度 × 4) - 12 字节几个实现上的特殊情况
- 某字段拿不到? 写保留值(4 字节
0xFFFFFFFF,或 8 字节全0xFF)表示"无效"。 - DSID 不认识怎么办? 二选一:填保留值占位、或整个跳过 INT 处理。
- 资源受限节点:可以只插部分字段,剩余部分用保留值填满到 Hop ML × 4;连一整段都写不下就直接跳过。
- 没写元数据的节点:不得递减 RemainingHopCnt——保持语义一致。
Sink 插自己数据的两种风格
Sink 也要记录自己这一跳的遥测,有两种做法:
- 像 Transit 那样压进栈里:最终作为遥测报告里的截断片段发出。
- 塞进遥测报告的"可选基础元数据 / 可选域专用元数据"字段(MX 风格,详见 §8.7):如果用这种方式,就不再适用 Checksum Complement,其对应位应清零;但源端专用元数据仍然会出现在截断栈里。
WARNING
一个 INT 节点实现上只能二选一,但接收端的遥测收集系统两种都要能解析。
字段修改权限速查
| 字段 | Source | Transit |
|---|---|---|
| Ver / D / M / Hop ML / RemainingHopCnt / Instruction Bitmap | 必须设 | 只能按规则改 E / M / RemainingHopCnt / DS Flags |
| Domain Specific 相关字段 | 可选设 | 不得修改 |
8.7 深入 INT-MX 头部
INT-MX 头同样是 12 字节的固定头,后面跟可选的源端插入元数据(变长,4 字节对齐):
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Ver = 2|D| Reserved |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Instruction Bitmap | Domain Specific ID (16b) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| DS Instruction (16b) | DS Flags |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 可选:域专用 Source-Inserted Metadata(变长,4B 对齐) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+相对 MD 头,少了 Hop ML 和 RemainingHopCnt——因为 MX 模式下根本不往包里压数据栈。
Instruction Bitmap 的含义
每一位对应 §7 中的一类标准元数据,常见位分配:
| bit | 含义 |
|---|---|
| 0 | Node ID |
| 1 | 一级入/出端口 ID |
| 2 | Hop Latency |
| 3 | Queue ID + 队列占用率 |
| 4 / 5 | 入/出时间戳(各 8 字节) |
| 6 | 二级端口 ID(入 + 出) |
| 7 | 出端口利用率 |
| 8 | Buffer ID + Buffer 占用率 |
| 9 – 14 | 其他基础位 |
| 15 – 31 | 保留 |
每个置位对应采 4 或 8 字节的元数据。
DS Instruction 的两种子模式
域专用指令位可以按两种语义使用:
- Export 模式:节点按指令采数据,然后上报。
- Source-Inserted 模式:源节点把元数据塞进包里,由谁消费则由策略决定:
- All Nodes:所有节点都要上报一份。
- Sink Node:只有 Sink 上报。
- None:只在网络内部用(比如引导路径决策),谁也不上报。
- 源端插入元数据的可变性:
- Source-Only:Source 写了就不能再改。
- Cumulative:Transit 和 Sink 可以更新或覆盖。
节点的处理流程
每一个 MX 节点(Source / Transit / Sink)都按下面的套路产遥测报告:
复制位图:把 INT-MX 头部里的
Instruction Bitmap/DS Instruction复制到遥测报告的RepMdBits/DSMdBits。特殊处理:
- Instruction Bitmap 里置了 bit 0(Node ID),那就清除
RepMdBits中的 bit 0——Node ID 已经在遥测报告通用头里带了,避免重复。 - 本地采不到的字段,对应位在遥测报告里清掉。
- Instruction Bitmap 里置了 bit 0(Node ID),那就清除
DSID 不认识:二选一——只报标准元数据并把
DSMdBits清零;或干脆什么都不发。处理 Source-Inserted Metadata:如果策略要求"All Nodes"或"Sink Node"上报,节点尽力把它带进遥测报告。两种方式:
- 把原始 INT-MX 头(含源插入元数据)嵌进遥测报告的 Individual Report 内容里。
- 解析后填入遥测报告的
Variable Optional Domain Specific Metadata字段(需要知道对应 DSID 和 DSMdBits 的定义,以保证顺序)。
WARNING
如果没走方式 2,就必须把对应的
DSMdBits清除。两种方式可以并存,但一个节点通常只用其中之一。域管理员将来定义新的 source-inserted 元数据时,要谨慎处理保留位。资源限制:能报多少报多少,相应更新
RepMdBits/DSMdBits。长度字段:遥测报告里的
MD Length、Variable Optional Baseline Metadata、Variable Optional Domain Specific Metadata都由上面这两个位图算出来。
字段修改权限速查
| 字段 | Source | Transit |
|---|---|---|
| Ver / D / Instruction Bitmap | 必须设 | 不得修改 |
| Domain Specific ID / DS Instruction / Source-Inserted Metadata | 可选设 | 不得修改 |
| DS Flags | — | 可改 |
INT 元数据总长度必须是 4 字节的倍数,这是硬性要求。
9 小结
- INT 的核心观点:把采集动作放进数据平面、放进每个包本身,而不是从外面问设备。
- 三角色:Source 写头,Transit 盖章(或上报),Sink 剥头上报。一个物理设备可以同时扮演多个角色。
- 三模式:XD 什么都不嵌,MX 只嵌指令,MD 指令+数据栈都嵌。三者是监控后端聚合复杂度 vs 数据包侵入度的权衡。
- 元数据:Node ID、出/入口 ID + 时间戳、Hop Latency、Queue/Buffer 占用率是最常用的几样,单位语义靠带外 YANG 模型对齐。
- 工程注意:MTU(建议预留 + PMTUD)、L4 校验和(直接改或 Checksum Complement)、拥塞(对无拥塞控制流量慎开)。