P4 Language
P4 全称是 Programming Protocol-independent Packet Processors,是一种网络编程语言,可以指定数据平面如何处理数据包。
1 安装
- 准备一个
Ubuntu 20.04 及以上版本操作系统; - 执行下面的命令;
sudo apt install git
git clone https://github.com/jafingerhut/p4-guide
./p4-guide/bin/install-p4dev-v8.sh |& tee log.txt- 每次进入新的
bash界面后都要执行source p4setup.bash才能运行 P4。可以直接把这行命令放到~/.bashrc文件里。
2 语法
预处理
P4 编译器支持 C 预处理器的部分功能:
#define#undef#if#else#endif#ifdef#ifndef#elif#include
与 C 类似,#include 可以在 "" 或者 <> 中指定文件名:
#include <system_file>
#include "user_file"核心库
所有 P4 程序必须导入核心库:
#include <core.p4>标识符
P4 标识符由字母、数字、下划线组成,不能以数字开头。只有单个下划线字符的特殊标识符 _ 被保留,用来接收不需要的值。
下表显示了所有 P4 保留关键字:
abstract action apply bit
bool const control default
else enum error extern
exit false header header_union
if in inout int
list match_kind out package
parser priority return select
state string struct switch
table this transition true
tuple type typedef value_set
varbit verify voidpriority
priority 自 P4-16 v1.2.4 起成为保留关键字,专门用于 entries 表项的优先级声明。
命名约定
- 内置类型全部小写,例如:
int<16> - 自定义类型首字母大写,例如:
IPv4Address - 类型变量全部大写,例如:
parser P<H, IH>() - 变量首字母小写,例如:
ipv4header - 常量全部大写,例如:
CPU_PORT - 错误和枚举使用驼峰形式,例如:
PacketTooShort
注释
- 单行注释:
// 注释内容 - 多行注释:
/* 注释内容 */
字面量类型
布尔
true 和 false 。
整数
整型为任意精度的非负整数,可以在数字前添加前缀指定进制:
- 十六进制:
0x或者0X - 八进制:
0o或者0O - 十进制:
0d或者0D - 二进制:
0b或者0B
默认进制
如果不加前缀指定进制,数字默认为十进制。
还可以在数字前再加一段 N w 或 N s 指定位宽与符号性,其中 N 是十进制宽度:
Nw表示宽度为N的无符号位串,对应类型bit<N>Ns表示宽度为N的有符号整数(二进制补码),对应类型int<N>
注意 w / s 本身不是"符号位",而是 bit<N> 与 int<N> 两种类型的宽度分隔符。
例子:
32w255 // 32位无符号数,值为255
32w0d255 // 同上
32w0xFF // 同上
32s0xFF // 32位有符号数,值为255
8w0b10101010 // 8位无符号数,值为170
8w0b_1010_1010 // 同上
8w170 // 同上
8s0b1010_1010 // 8位有符号数,值为-86
16w0377 // 16位无符号数,值为377(不是255!)
16w0o377 // 16位无符号数,值为255分隔符
可以在数字间添加下划线 _,让长数字更易读。例如上面的 8w0b_1010_1010。
注意
很多语言把前缀 0 视为八进制,相当于 0o,P4 则会当成十进制处理。例如上面的 0377,在 C 语言看来就是八进制的 0o377,相当于十进制的 255,而 P4 就会当成十进制的 377。
字符串
双引号括起来的字符组合,反斜杠可用于转义 \。
例子:
"simple string"
"string \" with \" embedded \" quotes"
"string with embedded
line terminator"尾随逗号
P4 允许逗号分隔的列表以逗号结尾。
例如,下面两种写法是一样的:
enum E {
a, b, c
}
enum E {
a, b, c,
}与预处理器指令结合相当有用:
enum E {
#if SUPPORT_A
a,
#endif
b,
c,
}参数修饰
in表示输入参数。该参数的值是从调用方传递给函数使用的,函数内部不会改变该值。out表示输出参数。该参数是用于从函数中返回值,通常在函数内部被修改后返回。inout表示既是输入参数也是输出参数。该参数在函数调用时传入,函数内部可以修改它的值,修改后的值会被返回。
无方向参数类似于被 in 修饰的参数。
仅允许为 in 或无方向参数提供默认参数值。
extern void f(in bit a, in bit<3> b = 2, in bit<5> c);
void g() {
f(a = 1, b = 2, c = 3); // 合法
f(a = 1, c = 3); // 合法,等价于上一个调用,b 使用默认值
f(1, 2, 3); // 合法,等价于上一个调用
f(1, 3); // 非法
}可选参数
带有 @optional 的参数是可选的,可选参数不能设置默认值。例如:
package pipeline(/* 参数 */);
package switch(pipeline first, @optional pipeline second);
pipeline(/* 参数 */) ingress;
switch(ingress) main; // 一个只有单级管道的交换机名称解析
P4 有一个顶层的无名命名空间,里面有全部的顶层声明。通过在标识符前加 .,该标识符将在顶层的命名空间解析。例如:
const bit<32> x = 2;
control c() {
int<32> x = 0;
apply {
x = x + (int<32>).x; // x 是 int<32> 的局部变量,
// .x 是顶层的 bit<32> 变量
}
}对标识符的解析是从内到外的,首先查找当前作用域,然后逐层向上查找。例如:
const bit<4> x = 1;
control p() {
const bit<8> x = 8; // 局部变量 x 的声明覆盖了全局 x
const bit<4> y = .x; // 当前使用的是顶层 x
const bit<8> z = x; // 当前为 p 的局部变量 x
apply {}
}基本数据类型
P4 的内置基本类型:void error string match_kind bool int bit<> int<> varbit<>
void 类型
空类型,类似 C 语言中的 void 类型。
error 类型
错误类型,所有 error 类型的常量,不论在哪定义的,都会被放进 error 命名空间内。error 类型类似于其他语言中的枚举 enum 类型。一个 P4 程序可以包含多个错误声明,编译器将这些声明合并在一起。
error { ParseError, PacketTooShort }match_kind 类型
match_kind 类型与 error 类型比较相似,用于声明表的键所支持的匹配方式(如精确匹配、三元匹配、最长前缀匹配等),而不是键本身。该类型声明的标识符都会放到顶层命名空间中。
P4 核心库(core.p4)声明了三种最基础的匹配方式:
match_kind {
exact,
ternary,
lpm
}具体架构(如 V1Model、PSA、TNA)还会再追加自己支持的匹配方式,例如 range、selector、optional 等。
match_kind 的声明
新的 match_kind 值只能由架构 / 模型描述文件声明,普通 P4 程序里不允许新增。
bool 类型
只有两个值,true 和 false 。
string 类型
字符串类型。P4 不支持对字符串进行操作,无法声明字符串类型的变量。字符串作为函数参数时,也只能是无方向的。
字符串常量
在 P4 程序中,唯一可以出现的字符串是字符串字面量常量。
整数类型
P4 支持任意大小的整数值。P4 的整型相较于 C 禁用了很多有模糊性的行为。比如,C 可以比较有符号数和无符号数,P4 则禁止对有符号数和无符号数的二元操作。
C 语言比较有符号数和无符号数
比较时,C 会将有符号类型提升为无符号类型,如果带符号数为负数,它将被转为一个很大的无符号数,导致对比结果不符合预期。例如:
int a = -1;
unsigned int b = 1;
if (a < b) {
// 代码块
}a 被提升为无符号整型,转换为一个相当大的数,导致 -1 < 1 为真。假设 int 类型为 4 字节,那实际比较的是 4294967295 < 1。
无符号整数
无符号整数也叫位串(bit-string),具有任意宽度。声明语法为:bit<W>,其中 W 是指定的位宽度。P4 允许宽度为 0,表示没有实际的位,值只能为 0。W 也可以是一个表达式,并且结果是非负整数,声明时表达式需要用括号括起来。例如:
const bit<32> x = 10; // 32位常量,值为10。
const bit<(x + 2)> y = 15; // 12位常量,值为15。
// 宽度的表达式必须使用括号。位串中的位从 0 到 W−1 编号。位 0 是最低有效位,而位 W−1 是最高有效位。
例如,类型 bit<128> 表示宽度为 128 位的位串值,其中位编号从 0 到 127,位 127 是最高有效位。
提示
bit 是 bit<1> 的简写。
有符号整数
有符号整数采用二进制补码表示。位宽为 W 的有符号整数声明为:int<W>,位 W-1 是符号位。
动态精度整数
varbit<W> 类型表示宽度最多为 W 位的位串。例如,varbit<120> 类型表示可以有 0 到 120 位的位串值。大多数适用于固定大小位串(bit<W>)的操作不能对动态大小的位串(varbit<W>)执行。
任意精度整数
该类型以 int 表示,仅用于整数字面量和仅包含字面量的表达式。例如:
const int a = 5;
const int b = 2 * a;
const int c = b - a + 3;如果函数参数类型是 int,则必须是无方向的。
整数字面量
整数字面量(常量)的类型如下:
- 一个简单的整数字面量的类型为
int。 - 一个以整数宽度
N和字符w为前缀的非负整数的类型为bit<N>。 - 一个以整数宽度
N和字符s为前缀的整数的类型为int<N>。
下表展示了若干整数字面量的示例及其类型。
| 字面量 | 类型 | 实际存储值 | 备注 |
|---|---|---|---|
10 | int | 10 | 任意精度 |
8w10 | bit<8> | 10 | 正好放得下 |
8s10 | int<8> | 10 | 正好放得下 |
2s3 | int<2> | -1 | 3 = 0b11,截到低 2 位 11,2 位补码即 -1(溢出) |
1w10 | bit<1> | 0 | 10 = 0b1010,截到低 1 位 0,所以存的是 0(溢出) |
1s1 | int<1> | -1 | 1 = 0b1,1 位补码 1 即 -1(溢出) |
派生类型
P4 提供的派生类型有:
enum(枚举)header(报头)header stacks(报头栈)struct(结构体)header_union(报头联合体)tuple(元组)list(列表)extern(外部类型)parser(解析器)control(控制器)package(包)
枚举类型
enum Suits { Clubs, Diamonds, Hearths, Spades }
enum bit<16> EtherType {
VLAN = 0x8100,
QINQ = 0x9100,
MPLS = 0x8847,
IPV4 = 0x0800,
IPV6 = 0x86dd
}报头类型
报头字段类型必须是有固定/可变位宽的类型,spec 允许下面这些:
bit<W>(无符号定长位串)int<W>(有符号定长整数)varbit<W>(最大宽度为W的变长位串,最多只能有一个出现在报头里)bool(编码为 1 位,1=true,0=false)- 可序列化枚举(即声明了基础类型的
enum bit<W>/enum int<W>) - 由上述类型组成的
struct
字段名称必须唯一。
报头还包含一个隐藏的"有效性"字段。当"有效性"字段为 true 时,该报头有效。当使用报头类型声明局部变量时,其"有效性"位会自动设置为 false。可以使用报头方法 isValid()、setValid() 和 setInvalid() 来操作此有效性位。
注意
报头不能嵌套其他报头、报头栈或报头联合体(但可以嵌套 struct)。
报头类型可以为空:
header Empty_h { }注意
即使是空报头也仍然包含一个有效性位。
当结构体位于报头内部时,调用的字段顺序与源代码中定义的字段顺序一致。例如:
struct ipv6_addr {
bit<32> Addr0;
bit<32> Addr1;
bit<32> Addr2;
bit<32> Addr3;
}
header ipv6_t {
bit<4> version;
bit<8> trafficClass;
bit<20> flowLabel;
bit<16> payloadLen;
bit<8> nextHdr;
bit<8> hopLimit;
ipv6_addr src;
ipv6_addr dst;
}不包含 varbit 字段的报头为“固定大小”报头。包含 varbit 字段的报头为“可变大小”报头。固定大小报头的大小(以位为单位)是所有组成字段大小的总和(不包括有效性位)。
例如,声明一个以太网报头:
header Ethernet_h {
bit<48> dstAddr;
bit<48> srcAddr;
bit<16> etherType;
}声明一个 Ethernet_h 类型的变量:
Ethernet_h ethernetHeader;P4 提供了一个 extract 方法,可用于从网络数据包中填充报头字段,extract 操作成功执行后,会将被提取报头的有效性位设置为 true。
报头栈
报头栈表示一个报头或报头联合体的数组.例如:
header Mpls_h {
bit<20> label;
bit<3> tc;
bit
bos;
bit<8> ttl;
}
Mpls_h[10] mpls;引入了一个名为 mpls 的报头栈,包含 10 个 Mpls_h 类型的报头。
报头联合体
报头联合体的每个字段都必须是报头类型。字段列表可以为空,且字段名称必须唯一。
例如,下面的 Ip_h 类型表示 IPv4 和 IPv6 的报头联合体:
header_union IP_h {
IPv4_h v4;
IPv6_h v6;
}结构体
结构体的字段名称必须唯一。空结构体(没有字段)是合法的。例如,下面的 Parsed_headers 结构体包含简单解析器识别的报头:
header Tcp_h { /* 字段省略 */ }
header Udp_h { /* 字段省略 */ }
struct Parsed_headers {
Ethernet_h ethernet;
Ip_h ip;
Tcp_h tcp;
Udp_h udp;
}元组
语法:tuple<类型列表>
例如:
tuple<int, bool>列表
列表包含任意个值,其中每个元素必须具有相同的类型。所有元素都是 T 类型的列表的类型写为:list<T>。
解析器类型
解析器应该至少有一个类型为 packet_in 的参数,代表正在处理的接收数据包。
例如,以下是一个名为 P 的解析器类型的声明,它以类型变量 H 进行参数化。该解析器接收一个 packet_in 值 b 作为输入,并产生两个值:
- 一个用户定义类型
H的值 - 一个预定义类型
Counters的值
struct Counters { /* 字段省略 */ }
parser P<H>(packet_in b,
out H packetHeaders,
out Counters counters);控制器类型
与解析器类型声明类似。
包类型
包的参数在编译时求值,所以它们必须是无方向的(不能是 in、out 或 inout)。
默认值
一些类型定义了默认值,可用于自动初始化该类型的值。
- 对于
int、bit<N>和int<N>类型,默认值为0。 - 对于
bool,默认值为false。 - 对于
error,默认值为error.NoError(在core.p4中定义)。 - 对于
string,默认值为空字符串""。 - 对于
varbit<N>,默认值为零位的串(当前没有P4字面量表示此值)。 - 对于
header,默认报头有效位为false。 - 对于
header stack,默认值为所有报头有效位为false且nextIndex为0。 - 对于
header_union,默认值为所有报头有效位为false。
注意
有些类型没有默认值,例如 match_kind、集合类型、函数类型、外部类型、解析器类型、控制器类型和包类型。
typedef
和 C 类似,例如:
typedef bit<32> u32;
typedef struct Point { int<32> x; int<32> y; } Pt;
typedef Empty_h[32] HeaderStack;也可以和泛型一起使用,例如:
struct S<T> {
T field;
}
typedef S X; // -- 非法:S没有类型参数
typedef S<bit<32>> X; // -- 合法3 类型转换
语法:(t) e,其中 t 是类型,e 是表达式。
3.1 显式类型转换
P4-16 spec §8.11.2 允许的显式转换有:
bit<1> <-> bool:0与false可以互转,1与true可以互转。bool只能与bit<1>互转,不能直接与int或int<W>转换。int<W> -> bit<W>:保持所有位不变,将符号位当成数值位处理。bit<W> -> int<W>:保持所有位不变,将最高位当成符号位处理。bit<W> -> bit<X>:如果W > X则截断该值,如果W < X则用0填充。int<W> -> int<X>:如果W > X则截断该值,如果W < X则用符号位填充。bit<W> -> int:保持值不变,转换为无限精度整数。int<W> -> int:保持值不变,转换为无限精度整数。int -> bit<W>:将二进制补码位串截断至W位。int -> int<W>:将二进制补码位串截断至W位。- 可序列化枚举与其基础类型之间可以互转。
- 用
type声明的类型与其基础类型之间可以互转。
不能一步完成的转换
bit<W> 与 int<X> 之间宽度不同时不能一步转换,必须先转宽度再转符号性(或反过来),例如 (int<8>)(bit<8>)y。
3.2 隐式类型转换
P4 只允许从 int 隐式转换到固定宽度类型,以及从具有基础类型的枚举隐式转为基础类型。
例如,对应下面这些声明:
enum bit<8> E {
a = 5
}
bit<8> x;
bit<16> y;
int<8> z;可以有以下这些隐式转换:
x + 1变x + (bit<8>)1z < 0变z < (int<8>)0x | 0xFFF变x | (bit<8>)0xFFF,会溢出x + E.a变x + (bit<8>)E.ax &&& 8变x &&& (bit<8>)816w11 << E.a变16w11 << (bit<8>)E.ax[E.a:0]变x[(bit<8>)E.a:0]E.a ++ 8w0变(bit<8>)E.a ++ 8w0
3.3 非法算术表达式
一些在 C 允许的算术表达式,在 P4 中不允许。例如,有如下声明:
bit<8> x;
bit<16> y;
int<8> z;下表列举了多个非法表达式,并给出了多种合法的替代写法:
| 表达式 | 错误原因 | 替代方案 |
|---|---|---|
x + y | 位宽不同 | (bit<16>)x + yx + (bit<8>)y |
x + z | 符号性不同 | (int<8>)x + zx + (bit<8>)z |
(int<8>)y | 不能同时修改符号性和位宽 | (int<8>)(bit<8>)y(int<8>)(int<16>)y |
y + z | 位宽和符号性均不同 | (int<8>)(bit<8>)y + z(bit<8>)y + (bit<8>)z(int<16>)y + (int<16>)z |
x << z | 位移符右侧不能是有符号数 | x << (bit<8>)z |
x < z | 符号性不同 | x < (bit<8>)z(int<8>)x < z |
1 << x | 对任意精度整数按位操作 | 32w1 << x |
~1 | 对任意精度整数按位操作 | ~32w1 |
5 & -3 | 对任意精度整数按位操作 | 32w5 & -3 |
4 集合的操作
4.1 单元素集合
例:
select (hdr.ipv4.version) {
4: continue;
}标签 4 表示包含整数值 4 的单元素集合。
4.2 全集
例:
select (hdr.ipv4.version) {
4: continue;
_: reject;
}default 或 _ 表示全集,它包含给定类型的所有可能值。
4.3 中缀运算符
&&&
中缀运算符 &&& 接受两个相同数值类型 T 的参数,产生一个 set<T> 类型的集合(不是同类型的单个值)。右侧充当掩码,掩码里为 0 的位代表"任意位"。常用于 select 表达式做三元匹配。
例如:
8w0x0A &&& 8w0x0F表示一个包含 16 种 bit<8> 值的集合,位模式为 XXXX1010,其中 X 可以是 0 或 1。
..
中缀运算符 .. 接受两个相同数值类型 T 的参数,并创建一个类型为 set<T> 的值。该集合包含两个数值间的所有数值,也包括这两个值。例如:
4s5 .. 4s8上面的式子表示一个包含4个连续 int<4> 值的集合:4s5、4s6、4s7 和 4s8。当式子中第二个值小于第一个值时,则表示一个空集合。
4.4 笛卡尔积
多个集合可以通过笛卡尔积进行组合:
select(hdr.ipv4.ihl, hdr.ipv4.protocol) {
(4w0x5, 8w0x1): parse_icmp;
(4w0x5, 8w0x6): parse_tcp;
(4w0x5, 8w0x11): parse_udp;
(_, _): accept;
}5 结构体的操作
通过点符号访问结构体字段:s.field。
只有在两个结构体具有相同类型且其所有字段都可以递归地进行比较时,才能进行相等(==)或不相等(!=)的比较。只有当两个结构体的所有对应字段都相等时,它们才被认为是相等的。
初始化结构体的两种方式
struct S {
bit<32> a;
bit<32> b;
}
const S x = { 10, 20 };
const S x = { a = 10, b = 20 };
const S x = (S) { a = 10, b = 20 };6 报头的操作
报头拥有与结构体相同的操作。此外,报头有“有效性”位,支持以下方法:
isValid()方法返回报头的“有效性”位的值。setValid()方法将报头的“有效性”位设置为true。setInvalid()方法将报头的“有效性”位设置为false。
报头的初始化方式与结构体类似,例如:
header H { bit<32> x; bit<32> y; }
H h;
h = { 10, 12 };
h = { y = 12, x = 10 };只有当两个报头类型相同时,才可以进行相等 (==) 或不等 (!=) 比较。两个报头相等的条件是它们有效位相同并且所有对应的字段都相等。
{#} 表示无效报头,可以是任意报头类型。例如:
header H { bit<32> x; bit<32> y; }
H h;
h = {#}; // 这会使报头 h 变为无效
if (h == {#}) { // 这相当于条件 !h.isValid()
// ...
}注意
这里的 # 字符不要误解为预处理指令。
7 报头栈的操作
报头栈是一个相同类型报头组成的数组。栈中的有效元素不需要是连续的。例如,下方伪代码是一个类型为 h[n] 的报头栈 hs:
// 类型声明
struct hs_t {
bit<32> nextIndex;
bit<32> size;
h[n] data; // 普通数组
}
// 实例声明和初始化
hs_t hs;
hs.nextIndex = 0;
hs.size = n;报头栈可以看作是一个包含报头数组 hs 和计数器 nextIndex 的结构体。nextIndex 用于简化构建报头栈解析器的过程,初始化为 0。
给定一个大小为 n 的报头栈 hs,下面的表达式都是合法的:
hs[index]:返回栈中指定位置的报头引用。hs.size:返回报头栈的大小。- 把一个报头栈赋值给另一个报头栈,要求类型完全相同。
hs的所有元素都会被复制,包括各个报头的有效位,以及nextIndex。
P4 提供了一些自动推进栈元素解析的运算:
hs.next:返回栈中索引为hs.nextIndex的元素引用。仅能在解析器中使用。如果栈的nextIndex >= size,则报错error.StackOutOfBounds。hs.last:返回栈中索引为hs.nextIndex - 1的元素引用,仅当该元素存在时有效。仅能在解析器中使用。如果nextIndex < 1 || nextIndex > size,则报错error.StackOutOfBounds。hs.lastIndex:返回索引hs.nextIndex - 1。仅能在解析器中使用。
P4 还给了一些操作报头栈前后元素的方法:
hs.push_front(int count):将hs向右移动count位。前count个元素变为无效,栈中的最后count个元素被丢弃。hs.nextIndex计数器增加count。返回类型为void。hs.pop_front(int count):将hs向左移动count位(即将索引为count的元素复制到索引为0的位置)。最后count个元素变为无效。hs.nextIndex计数器减少count。返回类型为void。
下面伪代码定义了 push_front 和 pop_front 的行为:
void push_front(int count) {
for (int i = this.size-1; i >= 0; i -= 1) {
if (i >= count) {
this[i] = this[i-count];
} else {
this[i].setInvalid();
}
}
this.nextIndex = this.nextIndex + count;
if (this.nextIndex > this.size) this.nextIndex = this.size;
// 注意:this.last, this.next 和 this.lastIndex 会随着 this.nextIndex 调整
}
void pop_front(int count) {
for (int i = 0; i < this.size; i++) {
if (i+count < this.size) {
this[i] = this[i+count];
} else {
this[i].setInvalid();
}
}
if (this.nextIndex >= count) {
this.nextIndex = this.nextIndex - count;
} else {
this.nextIndex = 0;
}
// 注意:this.last, this.next 和 this.lastIndex 会随着 this.nextIndex 调整
}与结构体和报头类似,两个报头栈可以进行相等 (==) 或不等 (!=) 比较,前提是它们具有相同的元素类型和长度。两个栈相等的条件是它们所有对应的元素都相等,nextIndex 的值不参与比较。
报头栈初始化示例:
header H<T> {
bit<32> b;
T t;
}
H<bit<32>>[3] s = (H<bit<32>>[3]){ {0, 1}, {2, 3}, (H<bit<32>>){#} };
// 不使用显式转换
H<bit<32>>[3] s1 = { {0, 1}, {2, 3}, (H<bit<32>>){#} };
// 使用默认初始化
H<bit<32>>[3] s2 = { {0, 1}, {2, 3}, ... };8 报头联合体的操作
header_union 无法初始化,且联合体和内部报头的有效位全为 false。
现在有如下报头和报头联合体:
header H1 {
bit<8> f;
}
header H2 {
bit<16> g;
}
header_union U {
H1 h1;
H2 h2;
}
U u; // u 无效可以通过给内部元素赋值使得报头联合体生效:
U u;
H1 my_h1 = { 8w0 }; // my_h1 有效
u.h1 = my_h1; // u 和 u.h1 都有效U u;
u.h2 = { 16w1 }; // u 和 u.h2 都有效或者直接修改它们的有效位:
U u;
u.h1.setValid(); // u 和 u.h1 都有效
H1 my_h1 = u.h1; // my_h1 现在有效,但包含一个未定义的值注意
读取未初始化的报头会得到乱七八糟的值,即使该报头本身是有效的。
读取报头联合体 u 中的一个报头 hi:u.hi。
对指定报头的有效位操作:
u.hi.setValid():将报头hi的有效位设置为true,同时把同一联合体里其他报头的有效位都置为false(联合体语义保证同一时刻至多一个成员有效)。u.hi.setInvalid():仅把hi的有效位设置为false,不影响其他成员(事实上由于"最多一个有效"的约束,调用前其他成员本来也已经是false)。
给报头联合体字段赋值的语句 u.hi = e,含义如下:
- 如果
e有效位为true,赋值语句等价于:
u.hi.setValid();
u.hi = e;- 如果
e有效位为false,赋值语句等价于:
u.hi.setInvalid();u.isValid() 的真正语义
spec §8.18 明确:"u.isValid() returns true if any of the headers in the union are valid"。即联合体里有任意一个成员有效,u.isValid() 就返回 true;全部无效时才返回 false。结合"最多一个有效"的约束,可以理解为:那唯一有效的成员是否存在。
报头联合体本身没有 setValid() 和 setInvalid() 方法,想置位只能通过具体成员 u.hi.setValid() / u.hi.setInvalid()。
下面的例子展示了如何使用 header_union 来统一表示 IPv4 和 IPv6 报头:
header_union IP {
IPv4 ipv4;
IPv6 ipv6;
}
struct Parsed_packet {
Ethernet ethernet;
IP ip;
}
parser top(packet_in b, out Parsed_packet p) {
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
16w0x0800 : parse_ipv4;
16w0x86DD : parse_ipv6;
}
}
state parse_ipv4 {
b.extract(p.ip.ipv4);
transition accept;
}
state parse_ipv6 {
b.extract(p.ip.ipv6);
transition accept;
}
}另一个例子使用 header union 来解析(选定的)TCP 选项:
header Tcp_option_end_h {
bit<8> kind;
}
header Tcp_option_nop_h {
bit<8> kind;
}
header Tcp_option_ss_h {
bit<8> kind;
bit<32> maxSegmentSize;
}
header Tcp_option_s_h {
bit<8> kind;
bit<24> scale;
}
header Tcp_option_sack_h {
bit<8> kind;
bit<8> length;
varbit<256> sack;
}
header_union Tcp_option_h {
Tcp_option_end_h end;
Tcp_option_nop_h nop;
Tcp_option_ss_h ss;
Tcp_option_s_h s;
Tcp_option_sack_h sack;
}
typedef Tcp_option_h[10] Tcp_option_stack;
struct Tcp_option_sack_top {
bit<8> kind;
bit<8> length;
}
parser Tcp_option_parser(packet_in b, out Tcp_option_stack vec) {
state start {
transition select(b.lookahead<bit<8>>()) {
8w0x0 : parse_tcp_option_end;
8w0x1 : parse_tcp_option_nop;
8w0x2 : parse_tcp_option_ss;
8w0x3 : parse_tcp_option_s;
8w0x5 : parse_tcp_option_sack;
}
}
state parse_tcp_option_end {
b.extract(vec.next.end);
transition accept;
}
state parse_tcp_option_nop {
b.extract(vec.next.nop);
transition start;
}
state parse_tcp_option_ss {
b.extract(vec.next.ss);
transition start;
}
state parse_tcp_option_s {
b.extract(vec.next.s);
transition start;
}
state parse_tcp_option_sack {
bit<8> n = b.lookahead<Tcp_option_sack_top>().length;
// n 是 TCP SACK 选项的总长度,以字节为单位。
// Tcp_option_sack_h 报头的 varbit 字段 'sack' 的长度因此为 n-2 字节。
b.extract(vec.next.sack, (bit<32>) (8 * n - 16));
transition start;
}
}与报头 header 类似,{#} 可以表示无效的报头联合体。例如:
header_union HU { ... }
HU h = (HU){#}; // 无效的报头联合体;等同于未初始化的报头联合。9 函数调用
在函数调用的时候,可以为每个参数都指定参数名。但是不能只指定一部分参数名,要么所有参数都指定参数名,要么都不指定。
例如:
extern void f(in bit<32> x, out bit<16> y);
bit<32> xa = 0;
bit<16> ya;
f(xa, ya); // 按照位置匹配参数
f(x = xa, y = ya); // 按照名称匹配参数
f(y = ya, x = xa); // 按照名称匹配参数,顺序任意
f(x = xa); // 错误:参数不够
f(x = xa, x = ya); // 错误:参数重复指定
f(x = xa, ya); // 错误:只有部分参数指定了名称
f(z = xa, w = yz); // 错误:没有名为 z 或 w 的参数
f(x = xa, y = 0); // 错误:y 必须是一个左值提示
上面例子中的最后一行,因为 y 的参数方向是 out,所以传进来的实参必须是一个可修改的左值(lvalue)。
10 构造函数的调用
以下结构拥有构造函数:
externparsercontrolpackage
例如:
extern ActionProfile {
ActionProfile(bit<32> size); // 构造函数
}
table tbl {
actions = { /* 省略内容 */ }
implementation = ActionProfile(1024); // 构造函数调用
}11 使用默认值初始化
通过默认值初始化的语法为 ...。例如:
struct S {
bit<32> b32;
bool b;
}
enum int<8> N0 {
one = 1,
zero = 0,
two = 2
}
enum N1 {
A, B, C, F
}
struct T {
S s;
N0 n0;
N1 n1;
}
header H {
bit<16> f1;
bit<8> f2;
}
N0 n0 = ...; // 使用默认值 0 初始化 n0
N1 n1 = ...; // 使用默认值 N1.A 初始化 n1
S s0 = ...; // 使用默认值 { 0, false } 初始化 s0
S s1 = { 1, ... }; // 使用值 { 1, false } 初始化 s1
S s2 = { b = true, ... }; // 使用值 { 0, true } 初始化 s2
T t0 = ...; // 使用值 { { 0, false }, 0, N1.A } 初始化 t0
T t1 = { s = ..., ... }; // 使用值 { { 0, false }, 0, N1.A } 初始化 t1
T t2 = { s = ... }; // 错误:未为字段 n0 和 n1 指定初始化器
tuple<N0, N1> p = { ... }; // 使用默认值 { 0, N1.A } 初始化 p
T t3 = { ..., n0 = 2}; // 错误:... 必须位于最后
H h1 = ...; // 初始化 h1 为无效的头
H h2 = { f2=5, ... }; // 初始化 h2 为有效的头,字段 f1 为 0,字段 f2 为 5
H h3 = { ... }; // 初始化 h3 为有效的头,字段 f1 为0,字段 f2 为012 函数声明
函数只能在最外层声明,并且所有参数都必须有方向。例如:
bit<32> max(in bit<32> left, in bit<32> right) {
return (left > right) ? left : right;
}提示
P4 不支持写递归函数。
13 常量声明
例如:
const bit<32> COUNTER = 32w0x0;
struct Version {
bit<32> major;
bit<32> minor;
}
const Version version = { 32w0, 32w0 };14 语句
P4 中的每个语句都必须以分号结尾。不同位置对语句的种类有些限制。例如,return 不能在 parser 中使用,switch 语句只能在 control 中使用。此外,parser 还支持一个 transition 语句。
14.1 赋值语句
赋值语句使用 = 编写。extern 类型不支持赋值操作。
14.2 空语句
空语句写作 ;,是一个无操作的语句。
14.3 块语句
块语句由大括号 {} 表示,包含一系列的语句,这些语句按顺序执行。块语句中的变量和常量只在块内可见。
14.4 Return 语句
return 语句立即终止包含它的 action、函数或 control 的执行;不允许出现在解析器 parser 中(parser 用 transition 转入终态)。
具体使用形式:
- 在
action、control、无返回值的函数中:写return;(不带表达式)即可。 - 在有返回值的函数中:必须写成
return expr;,且expr的类型要与函数返回类型匹配。
out 或 inout 参数的 copy-out 行为会在 return 语句执行后完成。
14.5 Exit 语句
exit 语句立即终止当前执行的所有块:当前动作 action(如果在动作 action 中调用)、当前控制块 control 及其所有调用者。exit 语句不允许出现在解析器 parser 或函数中。
任何方向为 out 或 inout 参数的复制行为都会在 exit 语句执行后完成。
14.6 条件语句
语法与大多数编程语言一样。
但是,P4 中的条件表达式必须是 bool 类型,而不能是整数类型。
当多个 if 语句嵌套时,else 会应用于最内层没有 else 语句的 if 语句。
14.7 Switch 语句
switch 语句只能在控制块 control 内使用。
switch 表达式有两种类型,在下面两个小节中描述。
14.7.1 使用 action_run 表达式的 Switch 语句
对于此类 switch 语句,表达式必须是 t.apply().action_run 的形式,其中 t 是一个表的名称。所有 switch 标签必须是表 t 的动作名称,或 default。例如:
switch (t.apply().action_run) {
action1: // fall-through 到 action2
action2: { /* 省略的主体 */ }
action3: { /* 省略的主体 */ } // action2 到 action3 标签无 fall-through
default: { /* 省略的主体 */ }
}14.7.2 使用整数或枚举类型表达式的 Switch 语句
对于此类 switch 语句,表达式必须是下面几种类型之一:
bit<W>int<W>enumerror
示例:
// 假设表达式 hdr.ethernet.etherType 的类型为 bit<16>
switch (hdr.ethernet.etherType) {
0x86dd: { /* 省略的主体 */ }
0x0800: // fall-through 到下一个主体
0x0802: { /* 省略的主体 */ }
0xcafe: { /* 省略的主体 */ }
default: { /* 省略的主体 */ }
}14.7.3 所有 switch 语句的通用说明
如果 switch 语句中的两个标签相等,则会产生编译时错误。switch 标签值不需要涵盖 switch 表达式的所有可能值。default 标签是可选的,如果使用 default,它必须是 switch 语句中的最后一个。
如果 switch 标签后没有跟随块语句,则会继续执行下一个标签;但如果存在块语句,则不会继续执行下一个标签。若最后一个 switch 标签后未跟随块语句,其行为等同于跟随了一个空块语句 {}。
注意
注意,这与 C 风格的 switch 语句不同,C 中需要使用 break 来防止继续执行。
如果没有标签与 switch 表达式相等,则:
- 如果存在
default标签,则执行带有default标签的块语句。 - 如果不存在
default标签,则不执行任何操作,继续执行switch语句后的代码。
15 数据包解析
15.1 解析器状态
P4 解析器具有一个起始状态和两个最终状态。起始状态名为 start,两个最终状态分别命名为 accept(表示解析成功)和 reject(表示解析失败)。start 状态是解析器的一部分,而 accept 和 reject 状态在逻辑上位于解析器之外。下图展示了解析器的一般结构:
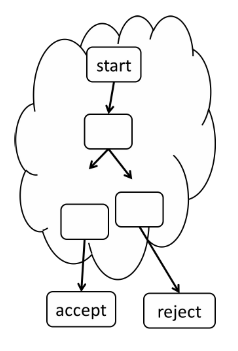
15.2 解析器声明
解析器声明包含一个名称、参数列表、可选的构造函数参数列表、局部元素以及解析器状态。
与解析器类型声明不同,解析器声明不能是泛型的。例如,以下声明是非法的:
parser P<H>(inout H data) { /* 省略主体 */ }在任何解析器中,至少必须存在一个状态,名为 start。解析器不能定义两个具有相同名称的状态。解析器也不能显式定义 accept 和 reject 状态。
在解析器状态之前,解析器还可以包含一个局部元素列表。这些局部元素可以是常量、变量,或者解析器中可能使用的对象实例化。
状态和局部元素共享相同的命名空间,因此,以下示例会产生错误:
// 错误示例
parser p() {
bit<4> t;
state start {
t = 1;
transition t;
}
state t { // 错误:名称 t 重复
transition accept;
}
}15.3 转换语句
解析器状态中的最后一条语句是一个可选的转换语句,用于将控制权转移到另一个状态,可能是 accept 或 reject。
例如,以下语句:
transition accept;终止当前解析器的执行,并立即转移到 accept 状态。
如果状态块的主体不以转换语句结束,则隐含的语句为:
transition reject;15.4 select 表达式
select 表达式会计算出一个状态。
select 表达式的典型用法是将最近提取的头字段的值与一组常量值进行比较,例如:
header IPv4_h { bit<8> protocol; /* 省略更多字段 */ }
struct P { IPv4_h ipv4; /* 省略更多字段 */ }
P headers;
select (headers.ipv4.protocol) {
8w6 : parse_tcp;
8w17 : parse_udp;
_ : accept;
}例如,要检测 TCP 保留端口(小于 1024),可以这样写:
select (p.tcp.port) {
16w0 &&& 16w0xFC00: well_known_port;
_: other_port;
}表达式 16w0 &&& 16w0xFC00 描述了最高有效的六位为零的 16 位值。
15.5 verify 语句
verify 语句提供了一种简单的错误处理方式。verify 只能在解析器中调用,语法上类似于一个具有以下签名的函数:
extern void verify(in bool condition, in error err);如果第一个参数为真,执行该语句不会产生任何影响。如果第一个参数为假,则会立即跳转到 reject 状态,导致解析过程立即终止;同时,与解析器关联的 parserError 将被设置为第二个参数 err 的值。
在 ParserModel 中,verify 语句的语义可以表示为:
ParserModel.verify(bool condition, error err) {
if (condition == false) {
ParserModel.parserError = err;
goto reject;
}
}15.6 数据提取
P4核心库中包含一个名为 packet_in 的内建 extern 类型声明,它表示传入的网络数据包。用户不能显式地实例化它,P4为每个传递给解析器 packet_in 参数提供一个独立的实例。
extern packet_in {
void extract<T>(out T hdr);
void extract<T>(out T variableSizeHeader,
in bit<32> variableFieldSizeInBits);
T lookahead<T>();
void advance(in bit<32> sizeInBits);
bit<32> length(); // 某些 target / 块(如 deparser)中此方法不可用
}要从类型为 packet_in 的参数 b 表示的数据包中提取数据,解析器调用 b 的 extract 方法。extract 方法有两个变体:一个参数的变体用于提取固定大小的报头,两个参数的变体用于提取可变大小的报头。由于这些操作可能导致运行时验证失败,这些方法只能在解析器中执行。
将数据提取到位串或整数时,第一个数据包位被提取到整数的最高有效位。
某些目标可能在所有字节接收完之前(即在数据包的长度已知之前)开始处理数据包,此时,packet_in.length() 无法使用。
在 ParserModel 中,packet_in 的语义可以使用以下数据包的抽象模型来描述:
packet_in {
unsigned nextBitIndex;
byte[] data;
unsigned lengthInBits;
void initialize(byte[] data) {
this.data = data;
this.nextBitIndex = 0;
this.lengthInBits = data.sizeInBytes * 8;
}
bit<32> length() { return this.lengthInBits / 8; }
}15.6.1 固定宽度提取
单参数 extract 方法处理固定宽度的报头,在 P4 中声明如下:
void extract<T>(out T headerLeftValue);例如,以下程序片段提取一个以太网头:
struct Result { Ethernet_h ethernet; /* 省略其他字段 */ }
parser P(packet_in b, out Result r) {
state start {
b.extract(r.ethernet);
}
}15.6.2 可变宽度提取
双参数的 extract 方法处理可变宽度的报头,在 P4 中声明如下:
void extract<T>(out T headerLvalue, in bit<32> variableFieldSize);以下示例展示了一种解析 IPv4 options 的方法,通过将 IPv4 报头分成两个单独的报头:
// 不带选项的IPv4报头
header IPv4_no_options_h {
bit<4> version;
bit<4> ihl;
bit<8> diffserv;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
bit<32> srcAddr;
bit<32> dstAddr;
}
header IPv4_options_h {
varbit<320> options;
}
struct Parsed_headers {
// 省略了一些字段
IPv4_no_options_h ipv4;
IPv4_options_h ipv4options;
}
error { InvalidIPv4Header }
parser Top(packet_in b, out Parsed_headers headers) {
// 省略了一些 state
state parse_ipv4 {
b.extract(headers.ipv4);
verify(headers.ipv4.ihl >= 5, error.InvalidIPv4Header);
transition select (headers.ipv4.ihl) {
5: dispatch_on_protocol;
_: parse_ipv4_options;
}
}
state parse_ipv4_options {
// 使用 IPv4 报头中的信息计算要提取的位数
b.extract(headers.ipv4options, (bit<32>)(((bit<16>)headers.ipv4.ihl - 5) * 32));
transition dispatch_on_protocol;
}
}ihl 字段
在 IPv4 报头中,ihl 是 "Internet Header Length"(互联网报头长度)的缩写。ihl 字段占4位,表示 IPv4 报头的长度,单位是 32 位字(即 4 字节)。该字段的最小值是 5,这表示没有 options 字段的 IPv4 报头长度为 20 字节。如果 ihl 的值大于 5,说明报头中包含了 options 字段。
如果 ihl 值小于 5,则会导致报头无效,因为这是非法的长度值。
15.6.3 预提取
lookahead 方法由 packet_in 提供,作用是预读当前位置上的 T 类型值——返回值正常拿到,但 nextBitIndex 不动,下一次 extract 仍然从同一个位置开始。与 extract 一样,如果数据包剩余比特不够 T 的宽度,lookahead 会跳转到 reject 状态并把 parserError 置为 error.PacketTooShort。
lookahead 方法可以如下调用:
b.lookahead<T>()其中,T 必须是固定宽度的类型。如果执行成功,lookahead 返回的结果是类型 T 的一个值。
在抽象模型 ParserModel 中,lookahead 的语义可以用以下伪代码表示:
T packet_in.lookahead<T>() {
bitsToExtract = sizeof(T);
lastBitNeeded = this.nextBitIndex + bitsToExtract;
ParserModel.verify(this.lengthInBits >= lastBitNeeded, error.PacketTooShort);
T tmp = this.data.extractBits(this.nextBitIndex, bitsToExtract);
return tmp;
}第 8 章中的 TCP 选项提取的例子也展示了 lookahead 的使用方式:
state start {
transition select(b.lookahead<bit<8>>()) {
0: parse_tcp_option_end;
1: parse_tcp_option_nop;
2: parse_tcp_option_ss;
3: parse_tcp_option_s;
5: parse_tcp_option_sack;
}
}
// 省略了一些状态
state parse_tcp_option_sack {
bit<8> n = b.lookahead<Tcp_option_sack_top>().length;
b.extract(vec.next.sack, (bit<32>) (8 * n - 16));
transition start;
}15.6.4 跳位
P4 提供了两种跳过数据包的位而不将其分配给报头的方法:
一种方法是将位提取到下划线标识符 _,并明确指定数据的类型:
b.extract<T>(_)另一种方法是在已知跳过的位数时,使用数据包的 advance 方法。
在抽象模型 ParserModel 中,advance 的含义用伪代码表示如下:
void packet_in.advance(bit<32> bits) {
// 目标允许包含以下行,但不需要
// verify(bits[2:0] == 0, error.ParserInvalidArgument);
lastBitNeeded = this.nextBitIndex + bits;
ParserModel.verify(this.lengthInBits >= lastBitNeeded, error.PacketTooShort);
this.nextBitIndex += bits;
}15.7 报头栈
报头栈具有两个属性 next 和 last,可用于解析。例如,下面的声明定义了一个栈,用于表示最多包含十个 MPLS 报头的数据包:
header Mpls_h {
bit<20> label;
bit<3> tc;
bit<1> bos;
bit<8> ttl;
}
Mpls_h[10] mpls;mpls.next 的类型为 Mpls_h,引用 mpls 栈中的一个元素。最初,mpls.next 引用栈的第一个元素。每当对它成功调用一次 b.extract(mpls.next),nextIndex 就 +1,从而 mpls.next 自动指向下一个槽位。属性 mpls.last 指向 nextIndex - 1 的元素(如果存在)。
边界条件:
- 当
nextIndex >= 报头栈大小时,访问mpls.next会跳转到reject,错误置为error.StackOutOfBounds; - 当
nextIndex == 0时,访问mpls.last同样跳转到reject并置error.StackOutOfBounds。
注意:直接对某个具体下标做 b.extract(mpls[i]) 不会改变 nextIndex,只有通过 .next 提取才会推进。
下面的例子展示了一个简化的 MPLS 处理解析器:
struct Pkthdr {
Ethernet_h ethernet;
Mpls_h[3] mpls;
// 其他报头省略
}
parser P(packet_in b, out Pkthdr p) {
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
0x8847: parse_mpls;
0x0800: parse_ipv4;
}
}
state parse_mpls {
b.extract(p.mpls.next);
transition select(p.mpls.last.bos) {
0: parse_mpls; // 这会形成一个循环
1: parse_ipv4;
}
}
// 其他状态省略
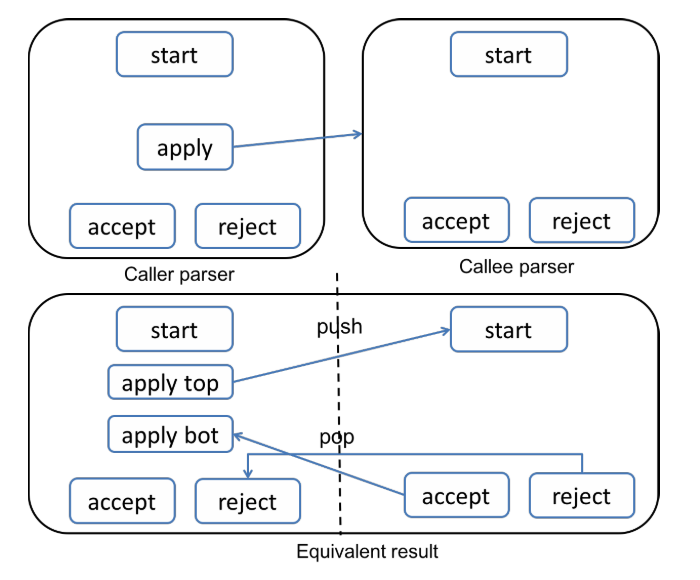
}15.8 子解析器
P4 允许解析器调用其他解析器的服务。需要先实例化该子解析器;然后通过调用其 apply 方法来调用实例的服务。例如:
parser callee(packet_in packet, out IPv4 ipv4) { /* 省略主体 */ }
parser caller(packet_in packet, out Headers h) {
callee() subparser; // callee 的实例
state subroutine {
subparser.apply(packet, h.ipv4); // 调用子解析器
transition accept; // 如果子解析器以 accept 状态结束,则接受
}
}子解析器调用的语义可以描述如下:
- 调用子解析器的状态在解析器调用语句处被拆分为两个 半状态。
- 顶部半状态包含对子解析器起始状态的转移。
- 子解析器的接受状态与当前状态的底部半状态对应。
- 子解析器的拒绝状态与当前解析器的拒绝状态对应。
下图展示了这一过程:
注意
P4 无法创建递归的解析器。
16 控制块
P4 解析器负责从数据包中提取数据到报头中。这些报头可以在控制块内进行操作和转换。
不能在控制块中实例化解析器。
P4 不支持控制块内的异常控制流。对控制流有非局部影响的唯一语句是 exit,它会导致执行当前控制块立即终止。也就是说,控制块中没有等同于解析器中的 verify 语句或 reject 状态的语句。因此,所有错误处理必须显式执行。
16.1 动作
动作是可以读取和写入正在处理的数据的代码片段。动作可以包含由控制平面写入、由数据平面读取的数据值。
在语法上,动作类似于没有返回值的函数。动作可以在控制块内声明,但是这样它们只能在该控制块的实例中使用。
以下例子展示了一个动作的声明:
action Forward_a(out bit<9> outputPort, bit<9> port) {
outputPort = port;
}动作参数不能具有 extern 类型。没有方向的动作参数(例如,上面例子中的 port)表示“动作数据”。所有此类参数必须出现在参数列表的末尾。
16.1.1 调用动作
动作可以通过两种方式执行:
- 隐式调用:通过表在 匹配-动作 处理期间执行。
- 显式调用:可以在控制块或其他动作中进行。在这两种情况下,所有动作参数的值必须明确提供,包括无方向参数的值。
提示
无方向参数的行为类似于 in 参数。
16.2 表
表描述了一个匹配-动作单元。匹配-动作单元的结构如下图所示:
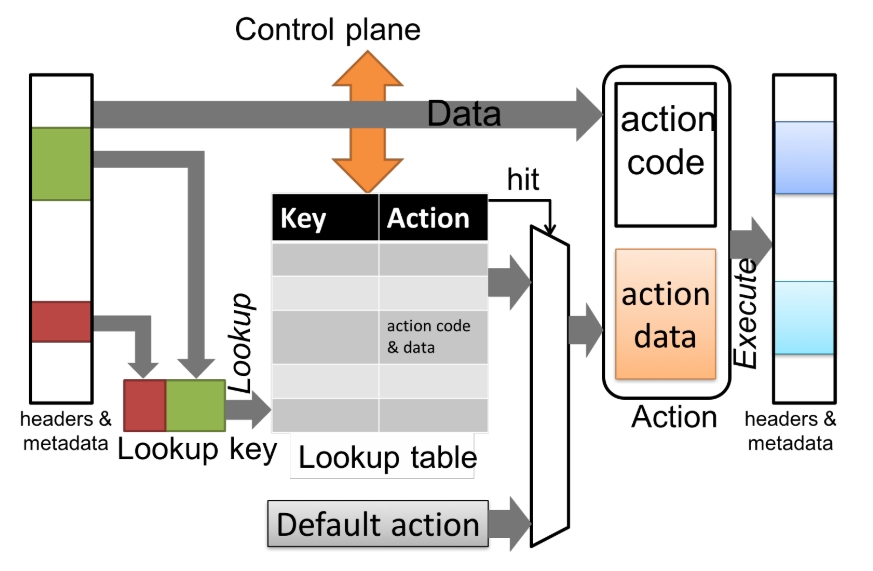
通过匹配-动作表处理数据包的步骤如下:
- 构造键。
- 在查找表中匹配键。匹配结果为一个动作。
- 执行动作,在输入数据上执行,导致数据发生变化。
查找表是一个有限映射,其内容由控制平面通过独立的控制平面API异步操作(读/写)。
标准的表属性包括:
key:一个表达式,描述了用于查找的键如何计算。actions:一个可能在表中找到的所有动作的列表。
此外,表还可以定义以下属性:
default_action:当查找表中的查找未能匹配键时执行的动作。size:指定表的期望大小的整数。entries:在加载P4程序时初始添加到表中的表项。largest_priority_wins:仅对包含entries属性的某些表有用。priority_delta:仅对包含entries属性的某些表有用。
对于未定义 default_action 属性的表,编译器会将其设置为 NoAction(并将其插入到动作列表中)。因此,所有表都可以被视为拥有一个隐式或显式的 default_action 属性。
被标记为 const 的属性不能由控制平面动态更改。键、动作和大小属性始终是常量,因此这些属性不需要 const 关键字。
16.2.1 表属性
16.2.1.1 键
键是一个表的属性。一个键是形如 (e : m) 的列表,其中 e 是描述要在表中匹配的数据的表达式,而 m 是描述用于执行查找的算法的 match_kind 常量。
例如,以下程序片段展示了一个键的定义:
table Fwd {
key = {
ipv4header.dstAddress : ternary;
ipv4header.version : exact;
}
}在这个例子中,键包含来自报头 ipv4header 的两个字段:dstAddress 和 version。match_kind 常量指定在运行时如何匹配数据平面值与表中的表项。
P4 核心库包含三个预定义的 match_kind 标识符:
match_kind {
exact,
ternary,
lpm
}三种匹配标识符的含义如下:
exact:键字段的值必须精确匹配表中的字段值。ternary:键字段使用值和掩码(value, mask)来匹配,遵循 P4 的掩码表达式语义。lpm(longest prefix match):最长前缀匹配,是ternary的一种特殊形式,掩码必须形如连续的 1 后接连续的 0(即前缀掩码1^k 0^(W-k),不允许中间夹 0 或 1)。
某些表项(尤其是包含 ternary 字段的表项)还需要优先级值。当键属于多个集合时,优先级高的表项会被首先匹配。
如果表没有 key 属性,或者其 key 属性的值是空元组 key = {},那么该表不包含查找表,只有默认动作。
16.2.1.2 动作
表必须声明可能出现在关联查找表中或默认动作的所有可能的动作,这通过 actions 属性来实现。例如:
action Drop_action() {
outCtrl.outputPort = DROP_PORT;
}
action Rewrite_smac(EthernetAddress sourceMac) {
headers.ethernet.srcAddr = sourceMac;
}
table smac {
key = { outCtrl.outputPort : exact; }
actions = {
Drop_action;
Rewrite_smac;
}
}- 在
smac表中的表项可能包含两种不同的动作:Drop_action和Rewrite_smac。 Rewrite_smac动作有一个参数sourceMac,在这种情况下,它将由控制平面提供。
表中的每个动作在动作列表中必须有一个唯一的名称。例如,下面例子就是错误的:
action a() {}
control c() {
action a() {}
// 非法表:有两个名称相同的动作
table t { actions = { a; .a; } }
}每个有方向(in、inout 或 out)的动作参数必须在动作列表中绑定;相反,没有方向的参数不能绑定在列表中。应用表(无论是通过 table1.apply().hit 这样的表达式直接调用,还是间接调用)在作为动作参数的表达式中是被禁止的。例如:
action a(in bit<32> x) { /* 省略主体 */ }
bit<32> z;
action b(inout bit<32> x, bit<8> data) { /* 省略主体 */ }
table t {
actions = {
a; // 错误,a 的参数 x 必须被绑定
a(5); // 将 a 的参数 x 绑定为 5
b(z); // 将 b 的参数 x 绑定为 z
b(z, 3); // 错误,不能绑定无方向的 data 参数
b(); // 错误,b 的 x 参数必须被绑定
a(table2.apply().hit ? 5 : 3); // 错误,不能在这里应用表
}
}16.2.1.3 默认动作
如果需要设置默认动作 default action,则必须写在 actions 属性之后。它可以被声明为 const,表示它不能由控制平面动态更改。默认动作必须是 actions 列表中出现的动作之一。传递给 in、out 或 inout 参数的表达式必须与 actions 列表中的某个元素使用的表达式在语法上完全相同。
例如,在上节的表中,我们设置如下默认动作(同时标记为常量):
const default_action = Rewrite_smac(48w0xAA_BB_CC_DD_EE_FF);继续上节的例子,以下是表 t 的一些默认动作:
default_action = a(5);
default_action = a(z); // 错误,a 的 x 参数在动作列表中已经绑定到 5
default_action = b(z,8w8); // 将 b 的 data 参数绑定到 8w8
default_action = b(z); // 错误,b 的 data 参数没有绑定
default_action = b(x, 3); // 错误,actions 列表里 b 的 x 参数已经绑定到 z,这里传 x 不匹配16.2.1.4 表项(Entries)
表项通常由控制平面安装,但也可以在编译时用一组表项初始化表。
使用 const entries 声明静态定义表项在实现固定算法的时候非常有用,编译器能够推断出表的实际用途,并有可能对资源做出更好的分配决策。
用 const entries 定义的表项是不可变的。控制平面只能读取它们,不能移除或修改任何表项,也不允许向这样的表中添加表项。
使用 entries(没有 const 修饰符)定义的表项可以在单个表项前加上 const。带有 const 的表项不能被控制平面修改或移除。没有 const 的表项可以由控制平面修改或移除。与使用 const entries 声明的表不同,控制平面可以向这样的表中添加表项(受表容量限制)。
如果源代码中未指定表项优先级,那么表项按程序顺序匹配,并在遇到第一个匹配项时停止。
根据键的 match_kind,键集表达式可以定义一个或多个表项。
示例:
header hdr {
bit<8> e;
bit<16> t;
bit<8> l;
bit<8> r;
bit<1> v;
}
struct Header_t {
hdr h;
}
struct Meta_t {}
control ingress(inout Header_t h, inout Meta_t m,
inout standard_metadata_t standard_meta) {
action a() { standard_meta.egress_spec = 0; }
action a_params(bit<9> x) { standard_meta.egress_spec = x; }
table t_exact_ternary {
key = {
h.h.e : exact;
h.h.t : ternary;
}
actions = {
a;
a_params;
}
default_action = a;
const entries = {
(0x01, 0x1111 &&& 0xF ) : a_params(1);
(0x02, 0x1181 ) : a_params(2);
(0x03, 0x1111 &&& 0xF000) : a_params(3);
(0x04, 0x1211 &&& 0x02F0) : a_params(4);
(0x04, 0x1311 &&& 0x02F0) : a_params(5);
(0x06, _ ) : a_params(6);
_ : a;
}
}
}在此示例中定义了一组 7 个表项,除最后一个表项外,所有表项都调用 a_params 动作。程序加载后,这些表项将按程序中列出的顺序安装到表中。
16.2.1.4.1 表项优先级(Entry priorities)
如果表的匹配字段都是 exact(精确匹配)或 lpm(最长前缀匹配),那么没有必要为其表项分配数值优先级。如果所有匹配字段都是精确匹配,则不允许存在重复的键,因此每次查找最多只能匹配一个表项,所以不需要设置优先级。如果存在 lpm 字段,则表项的优先级与前缀的长度相关。
对于相同的查找键可以同时匹配表中的多个表项的情况,控制平面 API 要求控制平面软件在向这样的表添加每个表项时提供一个数值优先级。这样,数据平面就可以确定哪个匹配表项是“赢家”。
数值优先级有两种常用但不同的方式:
largest_priority_wins:数值优先级为正整数,即 1 或更大,并规定优先级较大的表项胜出。称为“最大优先级胜出”。smallest_priority_wins:数值优先级为非负整数,即 0 或更大,并规定优先级较小的表项胜出。称为“最小优先级胜出”。
有个表属性 largest_priority_wins,值为 bool 类型。如果为 true,该表采用 largest_priority_wins(最大优先级胜出);如果为 false,则采用 smallest_priority_wins(最小优先级胜出)。
默认优先级属性
如果不指定 largest_priority_wins 属性,默认为 true,对应 largest_priority_wins。
有时可能希望初始的优先级值之间有“空隙”,方便以后插入新表项。一种方法是手动指定所有表项的优先级。另一种方法是通过表属性 priority_delta 实现,默认为 1,用作连续表项的优先级差值。
示例:
table t_exact_ternary {
key = {
h.h.e : exact;
h.h.t : ternary;
}
actions = {
a;
a_params;
}
default_action = a;
largest_priority_wins = false;
priority_delta = 10;
@noWarn("duplicate_priorities")
entries = {
const priority=10: (0x01, 0x1111 &&& 0xF ) : a_params(1);
(0x02, 0x1181 ) : a_params(2); // priority=20
(0x03, 0x1000 &&& 0xF000) : a_params(3); // priority=30
const (0x04, 0x0210 &&& 0x02F0) : a_params(4); // priority=40
priority=40: (0x04, 0x0010 &&& 0x02F0) : a_params(5);
(0x06, _ ) : a_params(6); // priority=50
}
}没有显式指定优先级的表项将被分配如注释中所示的优先级值。通常,此程序会发出多个表项具有相同优先级 40 的警告,但由于使用了 @noWarn("duplicate_priorities") 注解,这些警告将被抑制。
16.2.1.5 大小(Size)
size 是表的可选属性。值为整数,指定表项的数量。
16.2.2 表的调用
可以通过调用表的 apply 方法来调用表。调用表实例上的 apply 方法会返回一个包含三个字段的结构体类型的值。对于每个表 T,编译器生成一个枚举和一个结构,伪代码如下所示:
enum action_list(T) {
// 每个字段对应表 T 的动作列表中的一个动作
}
struct apply_result(T) {
bool hit;
bool miss;
action_list(T) action_run;
}apply 方法会在查找表中匹配成功时将 hit 字段设置为 true,并将 miss 字段设置为 false;如果未找到匹配,hit 会被设置为 false,而 miss 会被设置为 true。这些位可以用于调整控制块中的代码执行:
if (ipv4_match.apply().hit) {
// 有命中
} else {
// 未命中
}
if (ipv4_host.apply().miss) {
ipv4_lpm.apply(); // 只有在主机表未命中时才查找路由
}action_run 字段表示执行了哪种类型的动作(无论是命中还是未命中)。它可以用于 switch 语句:
switch (dmac.apply().action_run) {
Drop_action: { return; }
}16.2.3 表调用的原理
m.apply() 的原理如下方伪代码所示:
apply_result(m) m.apply() {
apply_result(m) result;
var lookupKey = m.buildKey(m.key);
action RA = m.table.lookup(lookupKey);
if (RA == null) { // 查找表未命中
result.hit = false;
RA = m.default_action; // 使用默认动作
} else {
result.hit = true;
}
result.miss = !result.hit;
result.action_run = action_type(RA);
evaluate_and_copy_in_RA_args(RA);
execute(RA);
copy_out_RA_args(RA);
return result;
}伪代码中 buildKey 的作用是按照键定义的顺序依次计算每个键表达式。
17 参数化
解析器 parser 和控制块 control 都可以通过构造函数参数进行额外的参数化。
构造函数参数必须是无方向的(即不能是 in、out 或 inout)。
示例:
parser GenericParser(packet_in b, out Packet_header p)
(bool udpSupport) { // 构造函数参数
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
16w0x0800: ipv4;
}
}
state ipv4 {
b.extract(p.ipv4);
transition select(p.ipv4.protocol) {
6: tcp;
17: tryudp;
}
}
state tryudp {
transition select(udpSupport) {
false: accept;
true : udp;
}
}
state udp {
// 省略主体
}
}在实例化 GenericParser 时,必须为 udpSupport 参数提供一个值,例如:
// topParser 是一个 GenericParser 实例,其中 udpSupport = false
GenericParser(false) topParser;17.1 直接调用
控制器和解析器通常被实例化一次。作为一种轻量级的语法糖,没有构造参数的控制器 control 和解析器 parser 可以直接调用,仿佛它们就是一个实例。这会导致创建并调用该类型的局部实例。例如:
control Callee(/* 参数省略 */) { /* 主体省略 */ }
control Caller(/* 参数省略 */)(/* 参数省略 */) {
apply {
Callee.apply(/* 参数省略 */); // Callee 被视为一个实例
}
}Caller 的定义等价于以下内容:
control Caller(/* 参数省略 */)(/* 参数省略 */) {
@name("Callee") Callee() Callee_inst; // Callee 的局部实例
apply {
Callee_inst.apply(/* 参数省略 */); // Callee_inst 被调用
}
}此特性旨在简化类型只被实例化一次的情况。语法上还允许对带泛型的控制器 control 或解析器 parser 进行直接调用:
control Callee<T>(/* 参数省略 */) { /* 主体省略 */ }
control Caller(/* 参数省略 */)(/* 参数省略 */) {
apply {
Callee<bit<32>>.apply(/* 参数省略 */); // Callee<bit<32>> 被视为一个实例
}
}多次对同一类型直接调用,实例归属规则如下:
- 同一作用域内的多次直接调用,复用同一个匿名实例(spec §14.2 原文:"Different direct type invocations from the same scope share the same anonymous instance"),等价于事先
Foo() foo_inst;然后两次foo_inst.apply()。 - 不同作用域内的直接调用,会各自创建独立的匿名实例。
对于需要构造参数的控制器或解析器,不能进行直接调用,必须在调用之前手动实例化。
18 反解析
解析的逆过程是反解析或构造数据包,P4 没提供单独的反解析语法,需要在带有参数类型 packet_out 的控制块中完成。
例如,下面的例子先在 packet_out 写入以太网报头,然后写入 IPv4 报头:
control TopDeparser(inout Parsed_packet p, packet_out b) {
apply {
b.emit(p.ethernet);
b.emit(p.ip);
}
}18.1 往数据包插入数据
数据类型 packet_out 在 P4 核心库中定义,以下是其定义的内容。它提供了一个名为 emit 的方法,用于将数据附加到输出数据包:
extern packet_out {
void emit<T>(in T data);
}emit 方法支持将报头 header、报头栈、结构体 struct 或报头联合体 header_union 中的数据附加到输出数据包中。
- 应用于报头:当且仅当报头 valid 时,将其字段按声明顺序写到 packet_out;invalid 时静默跳过,不会报错。
- 应用于报头栈:递归地对每个元素调用
emit,invalid 的元素自动跳过。 - 应用于结构体或报头联合体:递归地对每个字段调用
emit。
可序列化约束
能被 emit 写出去的数据,叶子字段必须有明确的位宽表示(即"可序列化"),spec 允许:bit<W>、int<W>、varbit<W>、bool、可序列化枚举(即写成 enum bit<8> X { ... } 这种带基础类型的枚举)。
不允许出现的:
- 没有基础类型的普通
enum errorstring、match_kind、extern等无固定 wire 表示的类型
下方伪代码展示了 emit 方法的原理:
packet_out {
byte[] data;
unsigned lengthInBits;
void initializeForWriting() {
this.data.clear();
this.lengthInBits = 0;
}
// 将数据追加到数据包中。类型 T 必须是报头、报头栈、报头联合体,或者由这些类型组成的结构体
void emit<T>(T data) {
if (isHeader(T))
if(data.valid$) {
this.data.append(data);
this.lengthInBits += data.lengthInBits;
}
else if (isHeaderStack(T))
for (e : data)
emit(e);
else if (isHeaderUnion(T) || isStruct(T))
for (f : data.fields$)
emit(e.f)
// 其他 T 类型的情况是非法的
}
}其中,valid$ 标识符表示报头的隐藏有效位,fields$ 表示结构体或报头联合体的字段列表。使用 for-each 语法来遍历栈中的元素(e : data)以及遍历结构体和报头联合体的字段列表(f : data.fields$)。对于结构体的迭代顺序是按照类型声明中字段的顺序进行的。
19 架构描述
架构描述形式为一个 P4 源文件,该文件至少有一个包 package 的声明。
该文件可能预定义数据类型、常量、错误,还需声明所有可编程模块的类型,包括解析器和控制块。这些模块可以选择性地组合到包中,包也可以嵌套。
19.1 架构描述示例
以下示例描述了一个交换机,有两个数据包,每个数据包有一个解析器、匹配-动作流水线(a match-action pipeline)、一个反解析器:
parser Parser<IH>(packet_in b, out IH parsedHeaders);
// ingress match-action pipeline
control IPipe<T, IH, OH>(in IH inputHeaders,
in InControl inCtrl,
out OH outputHeaders,
out T toEgress,
out OutControl outCtrl);
// egress match-action pipeline
control EPipe<T, IH, OH>(in IH inputHeaders,
in InControl inCtrl,
in T fromIngress,
out OH outputHeaders,
out OutControl outCtrl);
control Deparser<OH>(in OH outputHeaders, packet_out b);
package Ingress<T, IH, OH>(Parser<IH> p,
IPipe<T, IH, OH> map,
Deparser<OH> d);
package Egress<T, IH, OH>(Parser<IH> p,
EPipe<T, IH, OH> map,
Deparser<OH> d);
package Switch<T>(Ingress<T, _, _> ingress, Egress<T, _, _> egress);19.2 架构程序示例
为了构建架构程序,P4 程序必须为所有参数传递值来实例化顶层包,并在顶层命名空间中创建一个名为 main 的变量。
例如,给出以下类型声明:
parser Prs<T>(packet_in b, out T result);
control Pipe<T>(in T data);
package Switch<T>(Prs<T> p, Pipe<T> map);以及以下声明:
parser P(packet_in b, out bit<32> index) { /* 省略主体 */ }
control Pipe1(in bit<32> data) { /* 省略主体 */ }
control Pipe2(in bit<8> data) { /* 省略主体 */ }合法的顶层 main 变量声明:
Switch(P(), Pipe1()) main;以下声明是非法的:
Switch(P(), Pipe2()) main;后者的声明不正确,因为解析器 P 需要 T 为 bit<32>,而 Pipe2 需要 T 为 bit<8>。
我们也可以显式地为类型变量指定值(否则编译器需要推断这些类型变量的值):
Switch<bit<32>>(P(), Pipe1()) main;20 静态断言
P4 核心库包含两个 static_assert 函数的重载声明,定义如下:
extern bool static_assert(bool check, string message);
在编译时计算表达式check。如果表达式为false,停止编译并打印相应消息。extern bool static_assert(bool check);
同上,但使用默认消息。
示例:
const bool _check = static_assert(V1MODEL_VERSION > 20180000,
"Expected a v1 model version >= 20180000");如果 static_assert 返回 false,将导致程序编译立即终止并报错。
21 注解
注解是一种简单的机制,能够在不改变语法的情况下扩展 P4 语言。注解通过 @ 符号添加到类型、字段、变量上。非结构化注解有一个可选主体,而结构化注解有一个强制主体,至少包含一对方括号 []。
同一元素上的非结构化注解和结构化注解的名称不能相同。
正确示例:
@my_anno(1) table T { /* 省略主体 */ }
@my_anno[2] table U { /* 省略主体 */ } // OK,虽然注解名相同,但是在不同对象上错误示例:
@my_anno(1)
@my_anno[2] table U { /* 省略主体 */ } // Error,非结构化注解和结构化注解的不能同名同一元素上的非结构化注解可以有相同名称。
同一元素上的结构化注解不能有相同名称。
正确示例:
@my_anno(1)
@my_anno(2) table U { /* 省略主体 */ } // OK,同一元素上的非结构化注解名称可以相同错误示例:
@my_anno[1]
@my_anno[2] table U { /* 省略主体 */ } // Error,同一元素上的结构化注解名称不能相同21.1 非结构化注解的主体
@my_anno(注解主体)
21.2 结构化注解的主体
@my_anno[注解主体]
21.2.1 结构化注解示例
注解的主体列表为空:
@Empty[]
table t {
/* 省略主体 */
}注解的主体列表包含多种类型:
#define TEXT_CONST "hello"
#define NUM_CONST 6
@MixedExprList[1,TEXT_CONST,true,1==2,5+NUM_CONST]
table t {
/* 省略主体 */
}注解的主体列表为键值对列表:
@Labels[short="Short Label", hover="My Longer Table Label to appear in hover-help"]
table t {
/* 省略主体 */
}注解的主体列表为键值对列表,且包含多种类型:
@MixedKV[label="text", my_bool=true, int_val=2*3]
table t {
/* 省略主体 */
}不允许混合键值对与表达式列表:
@IllegalMixing[key=4, 5] // Error
table t {
/* 省略主体 */
}不允许键名相同:
@DupKey[k1=4,k1=5] // Error,有两个键都叫 k1
table t {
/* 省略主体 */
}不允许结构化注解名称相同:
@DupAnno[k1=4]
@DupAnno[k2=5] // Error,有两个结构化注解名称都叫 DupAnno
table t {
/* 省略主体 */
}不允许结构化注解和非结构化注解使用相同名称:
@MixAnno("Anything")
@MixAnno[k2=5] // Error,和上一行的非结构化的注解同名
table t {
/* 省略主体 */
}21.3 预定义注解
以小写字母开头的注解名称保留给了标准库和架构。下表显示了所有 P4 保留注解:
| 注解名称 | 作用 |
|---|---|
atomic | 指定原子执行 |
defaultonly | 动作只能出现在默认动作中 |
hidden | 从控制平面隐藏可控实体 |
match | 指定 value_set 中字段的 match_kind |
name | 指定本地控制平面名称 |
optional | 参数可选 |
tableonly | 动作不能是默认动作 |
deprecated | 构造已被弃用 |
noWarn | 具有字符串参数;抑制编译器警告 |
21.3.1 可选参数注解
package、parser、control、extern 等类型的构造函数可以使用 @optional 注解,表示该参数不是必须传的。
21.3.2 表动作列表上的注解
以下两个注解可用于向编译器和控制平面提供有关表中动作的附加信息。这些注解没有主体。
@tableonly:带有此注解的动作只能出现在表中,不能作为默认动作。@defaultonly:带有此注解的动作只能出现在默认动作中,不能出现在表中。
table t {
actions = {
a, // 可以出现在任何地方
@tableonly b, // 只能出现在表中
@defaultonly c, // 只能出现在默认动作中
}
/* 省略主体 */
}21.3.3 控制平面API注解
@name 注解指示编译器在生成操纵控制平面元素的外部 API 时使用不同的名称。该注解采用字符串字面量主体。在以下示例中,表的完全限定名称为 c_inst.t1:
control c( /* 参数省略 */ )() {
@name("t1") table t { /* 主体省略 */ }
apply { /* 主体省略 */ }
}
c() c_inst;@hidden 注解将可控实体(例如表、键、动作或外部)隐藏在控制平面中。有效地移除了它的完全限定名称。此注解没有主体。
21.3.3.1 限制
每个元素至多可以用一个 @name 或 @hidden 注解。并且每个控制平面名称至多只能引用一个可控实体。特别是在使用 @name 注解时,包含绝对路径名(即以点开头)的类型被实例化多次,将导致同一个名称引用两个可控实体。例如:
control noargs();
package top(noargs c1, noargs c2);
control c() {
@name(".foo.bar") table t { /* 主体省略 */ }
apply { /* 主体省略 */ }
}
top(c(), c()) main;如果没有 @name 注解,这个程序将生成两个具有完全限定名称的可控实体 main.c1.t 和 main.c2.t。然而,@name(".foo.bar") 注解将这两个实例中的表 t 重命名为 foo.bar,导致同一个名称引用两个可控实体,这是非法的。
完全限定名称
完全限定名称(Fully Qualified Name)是指在编程中用来唯一标识某个元素的名称,包括其所在的所有作用域或上下文信息。在P4语言中,完全限定名称通常由多个部分组成,如包名、控制器名、表名等,确保在同一程序中不同元素不会产生名称冲突。例如,main.c1.t 表示 c1 控制器中的表 t,位于 main 包中。
21.3.4 并发控制注解
注解 @atomic 可用于强制代码块进行原子执行。
21.3.5 值集注解
注解 @match 用于指定 value_set 字段的 match_kind 值,而不是默认值 exact。
21.3.6 弃用注解
注解 @deprecated 有一个必需的字符串参数,当程序使用被弃用的构造时,将由编译器打印该字符串。例如:
@deprecated("Please use the 'check' function instead")
extern Checker {
/* 省略主体 */
}21.3.7 无警告注解
注解 @noWarn 有一个必需的字符串参数,该参数表示将被抑制的编译器警告。例如,在声明上使用 @noWarn("unused") 将防止编译器在该声明未被使用的情况下发出警告。
22 例子:一个非常简单的交换机
P4 官方提供了一个完整示例,名为“非常简单的交换机”(Very Simple Switch),简称 VSS。具体架构和完整程序在下面两个小节。
22.1 VSS 架构
该架构的示意图如下所示:
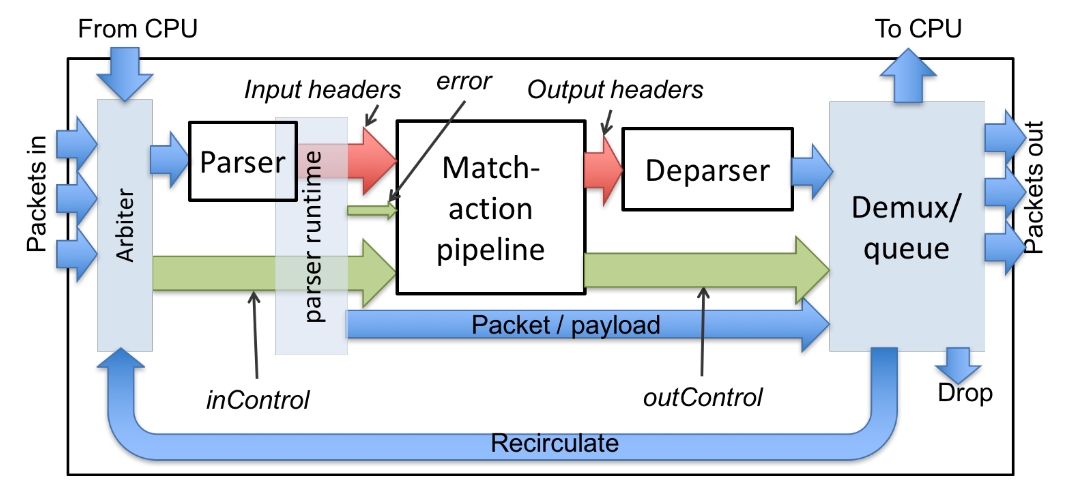
VSS 通过 8 个输入以太网端口、循环通道或直接连接到 CPU 的端口接收数据包。VSS 具有一个解析器,连接到单个匹配-动作流水线,再到单个反解析器。数据包经过反解析器后,通过 8 个输出以太网端口或 3 个“特殊”端口发出:CPU 端口(发送到控制平面)、Drop 端口(丢弃数据包)和 Recirculate 端口(通过特殊输入端口重新注入交换机)。白色块为可编程,需提供 P4 程序指定其行为。
下面是 P4 官方提供的 VSS 的声明:
// File "very_simple_switch_model.p4"
// Very Simple Switch P4 declaration
#include <core.p4>
/* Various constants and structure declarations */
typedef bit<4> PortId; // Ports are represented using 4-bit values
const PortId REAL_PORT_COUNT = 4w8; // Number of real ports (8)
/* Metadata accompanying an input packet */
struct InControl {
PortId inputPort;
};
/* Special input port values */
const PortId RECIRCULATE_IN_PORT = 0xD;
const PortId CPU_IN_PORT = 0xE;
/* Metadata that must be computed for outgoing packets */
struct OutControl {
PortId outputPort;
};
/* Special output port values for outgoing packet */
const PortId DROP_PORT = 0xF;
const PortId CPU_OUT_PORT = 0xE;
const PortId RECIRCULATE_OUT_PORT = 0xD;
/* Prototypes for all programmable blocks */
/**
* Programmable parser.
* @param <H> type of headers; defined by user
* @param b input packet
* @param parsedHeaders headers constructed by parser
*/
parser Parser<H>(packet_in b,
out H parsedHeaders);
/**
* Match-action pipeline
* @param <H> type of input and output headers
* @param headers headers received from the parser and sent to the deparser
* @param parseError error that may have surfaced during parsing
* @param inCtrl information from architecture, accompanying input packet
* @param outCtrl information for architecture, accompanying output packet
*/
control Pipe<H>(inout H headers,
in error parseError,
in InControl inCtrl,
out OutControl outCtrl);
/**
* VSS deparser.
* @param <H> type of headers; defined by user
* @param b output packet
* @param outputHeaders headers for output packet
*/
control Deparser<H>(inout H outputHeaders,
packet_out b);
/**
* Top-level package declaration - must be instantiated by user.
* @param <H> user-defined type of the headers processed.
*/
package VSS<H>(Parser<H> p,
Pipe<H> map,
Deparser<H> d);
// Architecture-specific objects that can be instantiated
// Checksum unit
extern Checksum16 {
Checksum16(); // Constructor
void clear(); // Prepare unit for computation
void update<T>(in T data); // Add data to checksum
void remove<T>(in T data); // Remove data from existing checksum
bit<16> get(); // Get the checksum for the data added since last clear
}22.2 VSS 完整程序
P4 官方也提供了完整的 VSS 程序代码,实现了基本的转发 IPv4 数据包的功能。
解析器尝试识别以太网报头和 IPv4 报头。若缺少这两个报头中的任何一个,解析都将报错并结束。否则,它会将这些报头中的信息提取到 Parsed_packet 结构体中。
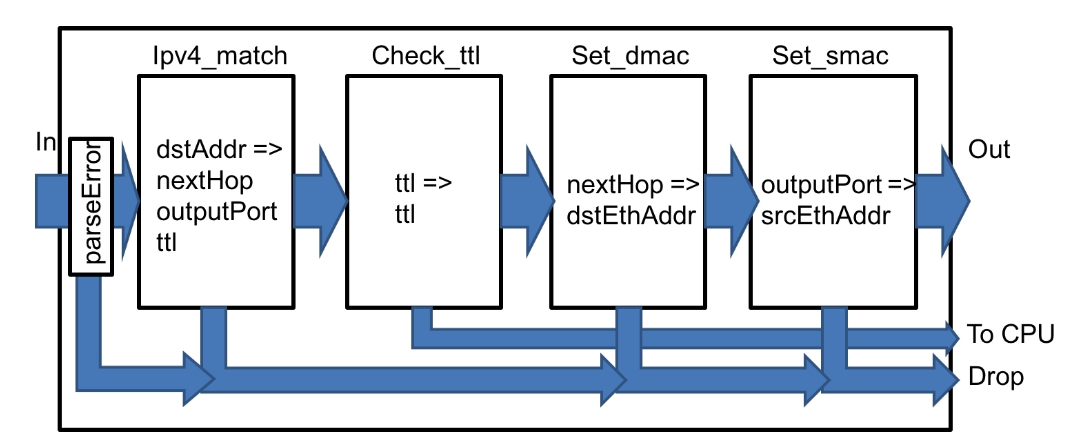
匹配-动作流程如上图所示。它包括四个匹配-动作单元:
- 第一个表使用 IPv4 目标地址来确定输出端口和下一跳的 IPv4 地址。如果查找失败,则丢弃数据包。该表递减 IPv4
ttl值。 - 第二个表检查
ttl值:如果ttl变为 0,则通过 CPU 端口将数据包发送到控制平面。 - 第三个表使用下一跳的 IPv4 地址(由第一个表计算)来确定下一跳的以太网地址。
- 最后,最后一个表使用
outputPort标识当前交换机的源以太网地址,该地址在传出数据包中设置。
完整代码如下:
// Include P4 core library
#include <core.p4>
// Include very simple switch architecture declarations
#include "very_simple_switch_model.p4"
// This program processes packets comprising an Ethernet and an IPv4
// header, and it forwards packets using the destination IP address
typedef bit<48> EthernetAddress;
typedef bit<32> IPv4Address;
// Standard Ethernet header
header Ethernet_h {
EthernetAddress dstAddr;
EthernetAddress srcAddr;
bit<16> etherType;
}
// IPv4 header (without options)
header IPv4_h {
bit<4> version;
bit<4> ihl;
bit<8> diffserv;
bit<16> totalLen;
bit<16> identification;
bit<3> flags;
bit<13> fragOffset;
bit<8> ttl;
bit<8> protocol;
bit<16> hdrChecksum;
IPv4Address srcAddr;
IPv4Address dstAddr;
}
// Structure of parsed headers
struct Parsed_packet {
Ethernet_h ethernet;
IPv4_h ip;
}
// User-defined errors that may be signaled during parsing
error {
IPv4OptionsNotSupported,
IPv4IncorrectVersion,
IPv4ChecksumError
}
// Parser section
parser TopParser(packet_in b, out Parsed_packet p) {
Checksum16() ck; // Instantiate checksum unit
state start {
b.extract(p.ethernet);
transition select(p.ethernet.etherType) {
0x0800: parse_ipv4; // IPv4 packets
// No default rule: all other packets rejected
}
}
state parse_ipv4 {
b.extract(p.ip);
verify(p.ip.version == 4w4, error.IPv4IncorrectVersion);
verify(p.ip.ihl == 4w5, error.IPv4OptionsNotSupported);
ck.clear();
ck.update(p.ip);
// Verify that packet checksum is zero
verify(ck.get() == 16w0, error.IPv4ChecksumError);
transition accept;
}
}
// Match-action pipeline section
control TopPipe(inout Parsed_packet headers,
in error parseError, // Parser error
in InControl inCtrl, // Input port
out OutControl outCtrl) {
IPv4Address nextHop; // Local variable
/**
* Indicates that a packet is dropped by setting the
* output port to the DROP_PORT
*/
action Drop_action() {
outCtrl.outputPort = DROP_PORT;
}
/**
* Set the next hop and the output port.
* Decrements ipv4 ttl field.
* @param ipv4_dest ipv4 address of next hop
* @param port output port
*/
action Set_nhop(IPv4Address ipv4_dest, PortId port) {
nextHop = ipv4_dest;
headers.ip.ttl = headers.ip.ttl - 1;
outCtrl.outputPort = port;
}
/**
* Computes address of next IPv4 hop and output port
* based on the IPv4 destination of the current packet.
* Decrements packet IPv4 TTL.
* @param nextHop IPv4 address of next hop
*/
table ipv4_match {
key = { headers.ip.dstAddr: lpm; } // Longest-prefix match
actions = {
Drop_action,
Set_nhop
}
size = 1024;
default_action = Drop_action;
}
/**
* Send the packet to the CPU port
*/
action Send_to_cpu() {
outCtrl.outputPort = CPU_OUT_PORT;
}
/**
* Check packet TTL and send to CPU if expired.
*/
table check_ttl {
key = { headers.ip.ttl: exact; }
actions = { Send_to_cpu, NoAction }
const default_action = NoAction; // Defined in core.p4
}
/**
* Set the destination MAC address of the packet
* @param dmac destination MAC address.
*/
action Set_dmac(EthernetAddress dmac) {
headers.ethernet.dstAddr = dmac;
}
/**
* Set the destination Ethernet address of the packet
* based on the next hop IP address.
* @param nextHop IPv4 address of next hop.
*/
table dmac {
key = { nextHop: exact; }
actions = {
Drop_action,
Set_dmac
}
size = 1024;
default_action = Drop_action;
}
/**
* Set the source MAC address.
* @param smac: source MAC address to use
*/
action Set_smac(EthernetAddress smac) {
headers.ethernet.srcAddr = smac;
}
/**
* Set the source mac address based on the output port.
*/
table smac {
key = { outCtrl.outputPort: exact; }
actions = {
Drop_action,
Set_smac
}
size = 16;
default_action = Drop_action;
}
apply {
if (parseError != error.NoError) {
Drop_action(); // Invoke drop directly
return;
}
ipv4_match.apply(); // Match result will go into nextHop
if (outCtrl.outputPort == DROP_PORT) return;
check_ttl.apply();
if (outCtrl.outputPort == CPU_OUT_PORT) return;
dmac.apply();
if (outCtrl.outputPort == DROP_PORT) return;
smac.apply();
}
}
// Deparser section
control TopDeparser(inout Parsed_packet p, packet_out b) {
Checksum16() ck;
apply {
b.emit(p.ethernet);
if (p.ip.isValid()) {
ck.clear(); // Prepare checksum unit
p.ip.hdrChecksum = 16w0; // Clear checksum
ck.update(p.ip); // Compute new checksum
p.ip.hdrChecksum = ck.get();
}
b.emit(p.ip);
}
}
// Instantiate the top-level VSS package
VSS(TopParser(), TopPipe(), TopDeparser()) main;